

学习目标:
- 学习获得下一篇文章的url的方法
- 利用“下一篇”功能抓取wordpress全部文章
测试环境:
win7 旗舰版
Python 2.7.14(Anaconda2 2 5.0.1 64-bit)
一、创建项目
创建一个名为URLteam的项目。
二、设置Items.py
代码如下:
# -*- coding:utf-8 -*-
from scrapy.item import Item, Field
class UrlteamItem(Item):
article_name = Field()
article_url = Field()
三、设置pipelines.py
import json
import codecs
class UrlteamPipeline(object):
def __init__(self):
self.file = codecs.open('urlteam_data.json', mode='wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
四、设置settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for urlteam project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
#
BOT_NAME = 'URLteam'
SPIDER_MODULES = ['URLteam.spiders']
NEWSPIDER_MODULE = 'URLteam.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'urlteam (+https://www.urlteam.org)'
#禁止cookies,防止被ban
COOKIES_ENABLED = False
ITEM_PIPELINES = {
'URLteam.pipelines.UrlteamPipeline':300
}
五、spiders目录下建立urlteam.py
注意:from URLteam.items import UrlteamItem 这一句,URLteam.items中的URLteam是指项目的名称,UrlteamItem是Items.py中的类名称。
也可以写成:
from ..items import UrlteamItem
或者
from ..items import *
#!/usr/bin/python
# -*- coding:utf-8 -*-
# from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from URLteam.items import UrlteamItem
class URLteamSpider(Spider):
name = "urlteam"
#减慢爬取速度 为1s
download_delay = 1
allowed_domains = ["urlteam.org"]
start_urls = [
"https://www.urlteam.org/2016/06/scrapy-%E5%85%A5%E9%97%A8%E9%A1%B9%E7%9B%AE-%E7%88%AC%E8%99%AB%E6%8A%93%E5%8F%96w3c%E7%BD%91%E7%AB%99/"
]
def parse(self, response):
sel = Selector(response)
#items = []
#获得文章url和标题
item = UrlteamItem()
article_url = str(response.url)
article_name = sel.xpath('//h1/text()').extract()
item['article_name'] = [n.encode('utf-8') for n in article_name]
item['article_url'] = article_url.encode('utf-8')
yield item
#获得下一篇文章的url
urls = sel.xpath('//div[@class="nav-previous"]/a/@href').extract()
for url in urls:
print url
yield Request(url, callback=self.parse)
六、测试
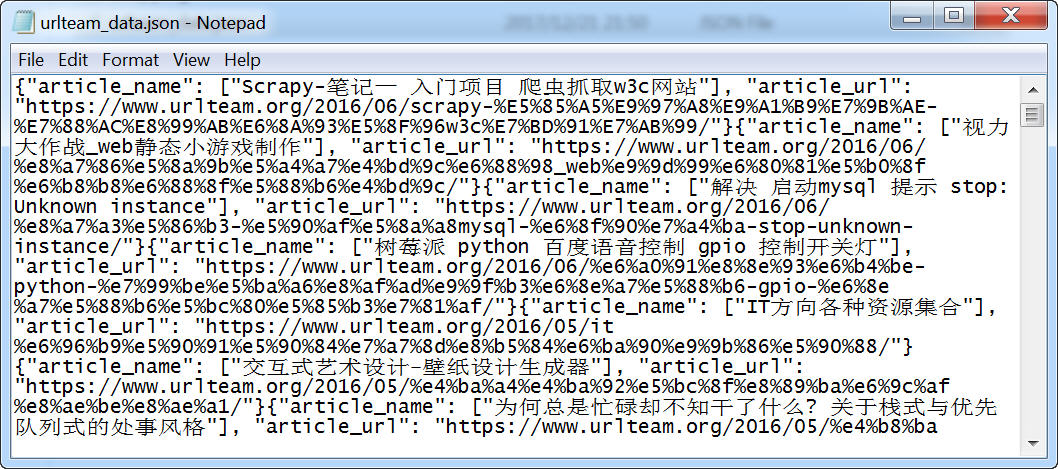
在urlteam项目根目录下运行,就会生成一个urlteam_data.json文件。
scrapy crawl urlteam
七、完善爬虫
上面的设定只是爬取了文章的标题和URL,下面我们通过修改代码,抓取文章内容。
修改:Items.py,在末尾加多一行。
article_content = Field()
修改urlteam.py,添加article_content的相关内容。
article_url = str(response.url)
article_name = sel.xpath('//h1/text()').extract()
article_content = sel.xpath('//div[@class="entry-content"]/p/text()').extract()
item['article_name'] = [n.encode('utf-8') for n in article_name]
item['article_url'] = article_url.encode('utf-8')
item['article_content'] = [n.encode('utf-8') for n in article_content]
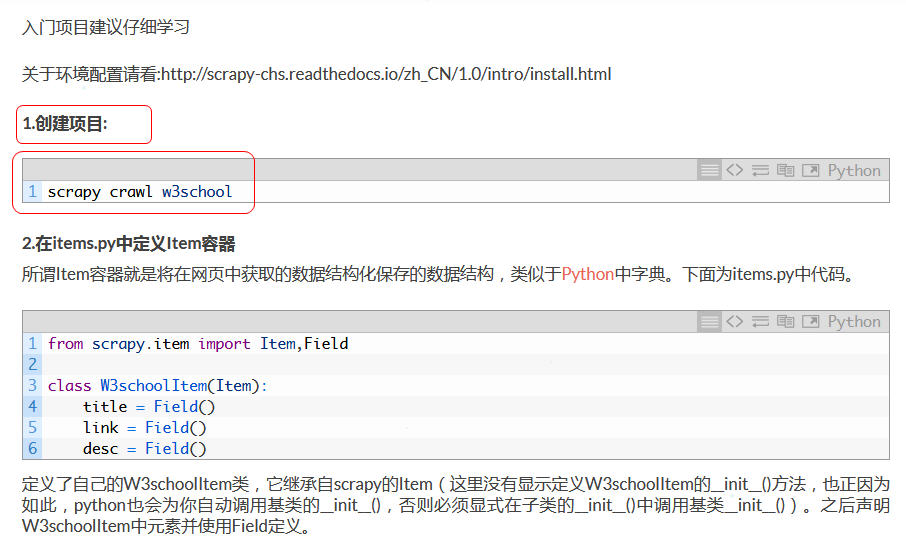
通过上面的设定,我们就可以抓取纯文本的wordpress文章了,但是因为在使用xpath的时候,提取的是entry-content下面的P标签里的内容,所以网页中的一些加粗文字(包含在strong标签内)、代码(如下图中的红框内的内容)没有抓取到。
我们还要对代码进一步完善。
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。