一、知识点:
1.urljoin
response.urljoin():将相对网址拼接成绝对网址。
比如:
url = response.body_as_unicode() url = response.urljoin(url)
这样就能在url前拼接上https:
二、步骤
1.新建爬虫
scrapy startproject travalcity cd travalcity scrapy genspider travelspider travel.cn
2.新建Item (决定抓取哪些项目)
class TravalcityItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #标题
desc =scrapy.Field() #简介
3.编写爬虫文件travelspider.py (决定怎么爬)
import scrapy
from scrapy.selector import Selector
from travalcity.items import *
class TravelspiderSpider(scrapy.Spider):
name = "travelspider"
allowed_domains = ["bytravel.cn"]
start_urls = ['http://wap.bytravel.cn/view/index3480_list.html']
def parse(self, response):
for href in response.xpath("//ul[@id='titlename']/li/a/@href").extract():
item=TravalcityItem()
href = "http://wap.bytravel.cn"+href
print(href)
request=scrapy.http.Request(response.urljoin(href),callback=self.parse_desc)
request.meta['item']=item
yield request
def parse_desc(self,response):
item=response.meta['item']
item['title']=response.xpath("//h1").extract()
item['desc']=response.xpath("//article/div[3]").extract()
yield item
如果用xpath提取的url不是完整的域名,这时就需要使用urljoin进行拼接,传递任何url给urljoin可以将url的主域名取出来。
附另外一种写法:
from scrapy.http import Request from urllib import parse #python3用法 for post_url in post_urls: yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
全代码:
import scrapy
from scrapy.selector import Selector
from travalcity.items import *
from urllib import parse
class TravelspiderSpider(scrapy.Spider):
name = "travelspider"
allowed_domains = ["bytravel.cn"]
start_urls = ['http://wap.bytravel.cn/view/index3480_list.html']
def parse(self, response):
for href in response.xpath("//ul[@id='titlename']/li/a/@href").extract():
# href = "http://wap.bytravel.cn"+href
print(href)
request=scrapy.http.Request(url=parse.urljoin(response.url,href),callback=self.parse_desc)
yield request
next_page=response.xpath("//nav[@id='list-page']/ul/li[last()-0]/a/@href").extract_first()
last_page=response.xpath("//nav[@id='list-page']/ul/li[last()-1]/a/@href").extract_first()
if last_page:
next_page="http://wap.bytravel.cn/view/"+next_page
yield scrapy.http.Request(next_page,callback=self.parse)
def parse_desc(self,response):
item=TravalcityItem()
item['title']=response.xpath("//h1/text()").extract()[0]
item['desc'] = response.xpath("//article/div[3]/text()").extract()+response.xpath("//article/div/p/text()").extract()
tempItem = ""
for x in item['desc']:
x =x.replace('\r\n','')
x =x.replace('\r\n\r\n\r\n','')
tempItem = tempItem + x
item['desc']= tempItem
item['province']=response.xpath('//div[@id="mainbao"]/a[2]/text()').extract()[0]
item['city']=response.xpath('//div[@id="mainbao"]/a[3]/text()').extract()[0]
yield item
4、测试
在“C:\Users\Kevin\travelspider\travalcity\travalcity>”文件夹下面执行下面的命令:
scrapy crawl travelspider -0 woodenrobot.csv scrapy crawl travelspider -0 woodenrobot.json
注意,是o,不是0。
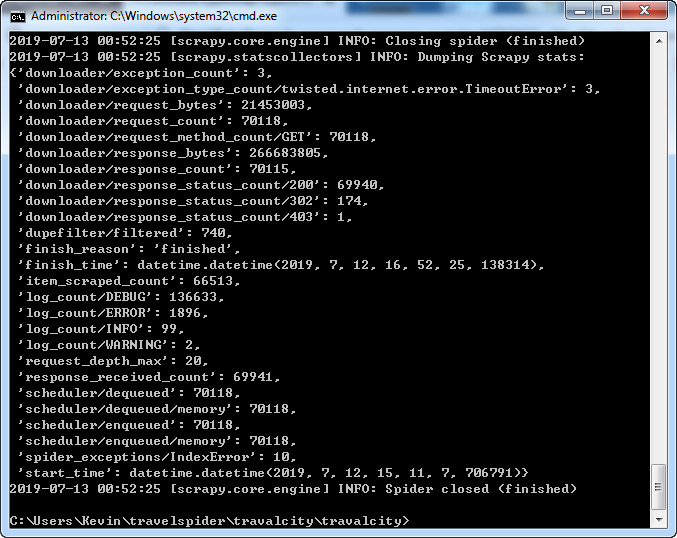
发现通过上面的输出,输出的csv乱码,输出的json也是编码不对。
这里只需要加上参数就可以了:
scrapy crawl travelspider -o woodenrobot.json -s FEED_EXPORT_ENCODING='utf-8'
5.修改pipilines.py (决定爬取后的内容怎么样处理)
import sqlite3
import pymysql.cursors
class TravalcityPipeline(object):
def open_spider(self, spider):
self.con = pymysql.connect(
host='127.0.0.1',#数据库地址
port=3306,# 数据库端口
db='testscrapy', # 数据库名
user = 'root', # 数据库用户名
passwd='', # 数据库密码
charset='utf8', # 编码方式
use_unicode=True)
self.cu = self.con.cursor()
def process_item(self, item, spider):
print(spider.name, 'pipelines')
insert_sql = "insert into test (title,content) values('{}','{}')".format(item['title'], item['desc'])
print(insert_sql) # 为了方便调试
self.cu.execute(insert_sql)
self.con.commit()
return item
def spider_close(self, spider):
self.con.close()
6.修改settings.py (决定由谁去处理爬取的内容)
取消下面的代码的注释即可。
ITEM_PIPELINES = {
'travalcity.pipelines.TravalcityPipeline': 300,
}
8.查看效果
这里最好使用Navicat来建立数据库,并将id设为“自动递增”以及为主键。
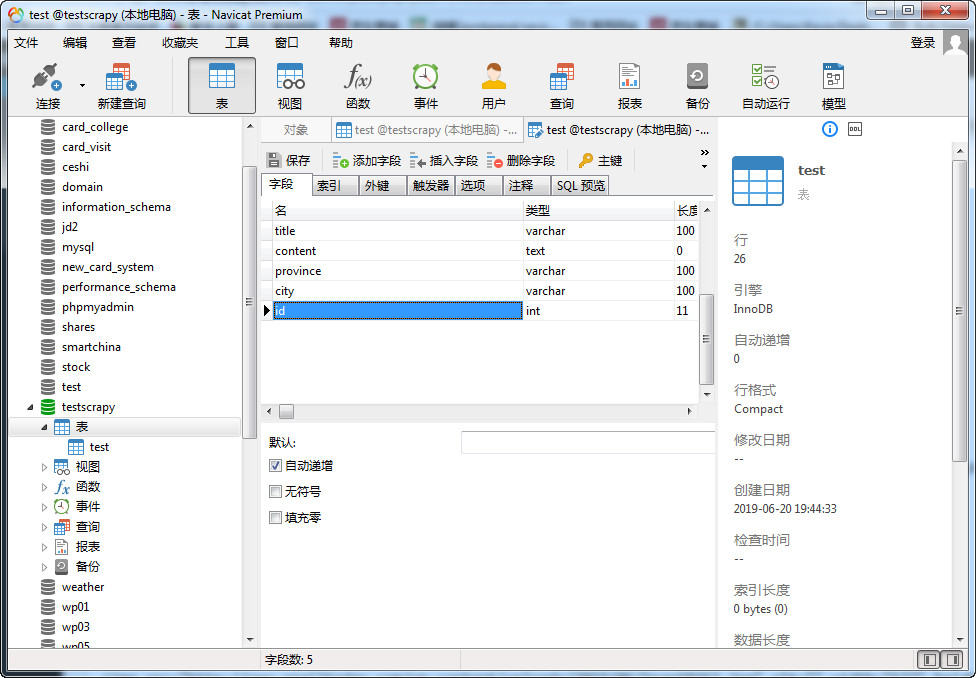
备注:下面还可以设置默认值。
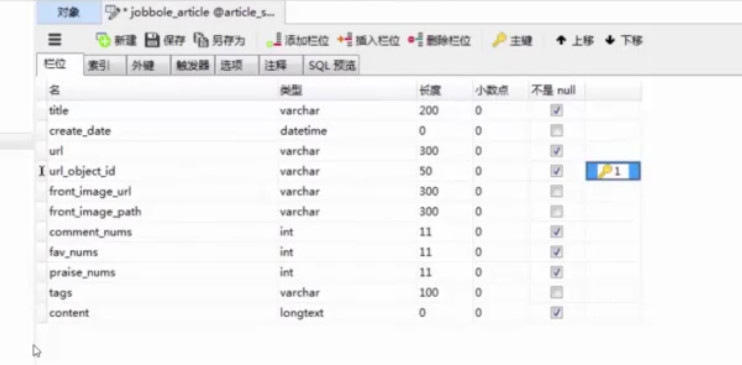
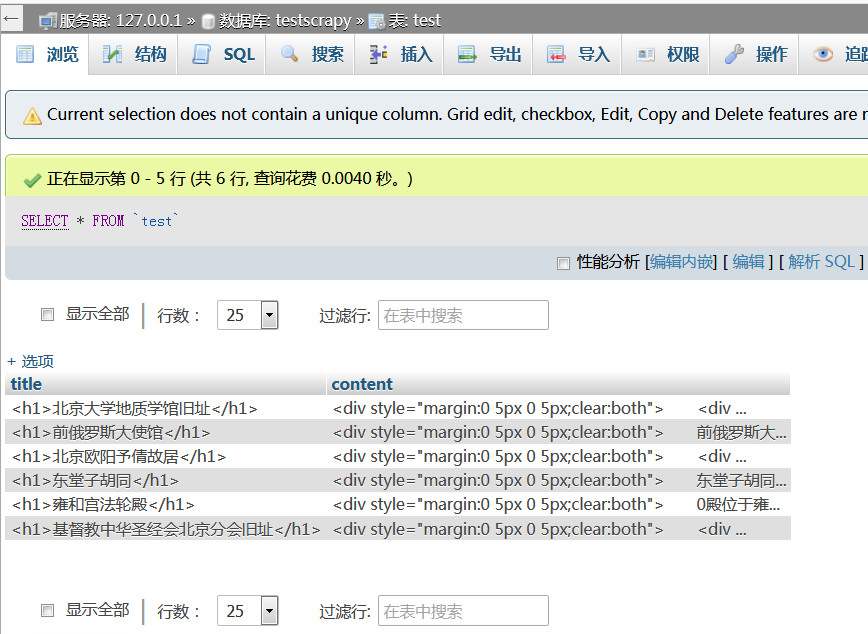
可以看到已经成功地插入到数据库。
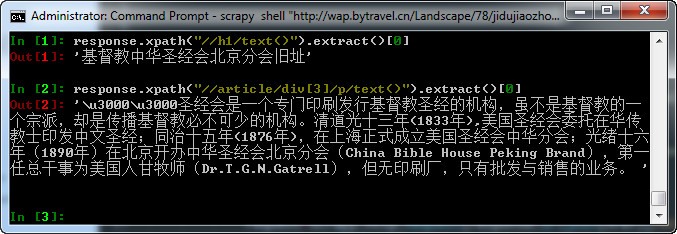
9. shell测试
直接执行以下命令:
scrapy shell "http://wap.xx.com"
response.xpath("//h1/text()").extract()[0]
10.去除'/r/n'
采集的结果中有许多'/r/n',在网上找了解决方案,说是可以使用normalize-space这个函数,但是我使用这个函数后,发现抓取的数据不全,比如明明一篇文章,未使用这个函数可以抓取到全部文件,使用了这个函数之后,后面有两段文章抓取不到。所以最后只能用字符串替换的方法来解决。
11、url函数
因为我是分块抓取的,所以另外写了一个函数,再使用start_urls = readUrl()将所有url加入到了起始url。
def readUrl():
data = []
for line in open("url.txt","r"): #设置文件对象并读取每一行文件
line = line.replace("\n","")
data.append(line) #将每一行文件加入到list中
return data
三、使用SQlite保存数据
1.新建sqlite数据库及数据表
最好的方法是使用Navicat,方法如下:
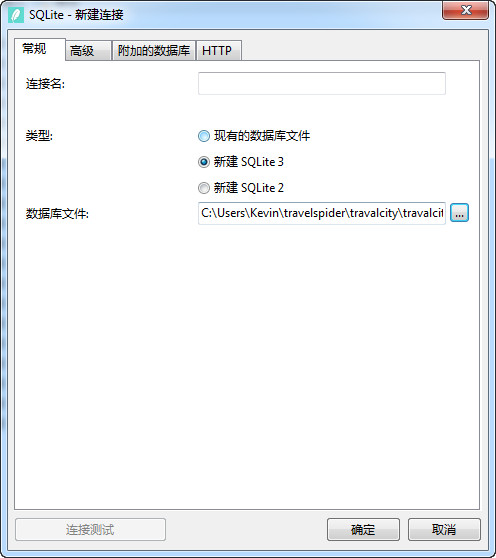
这里选择“新建SQlite3”,并将数据库文件的存储位置设置为执行“scrapy crawl xxx”命令的文件夹。
打开刚刚建立的数据库,开始新建数据表
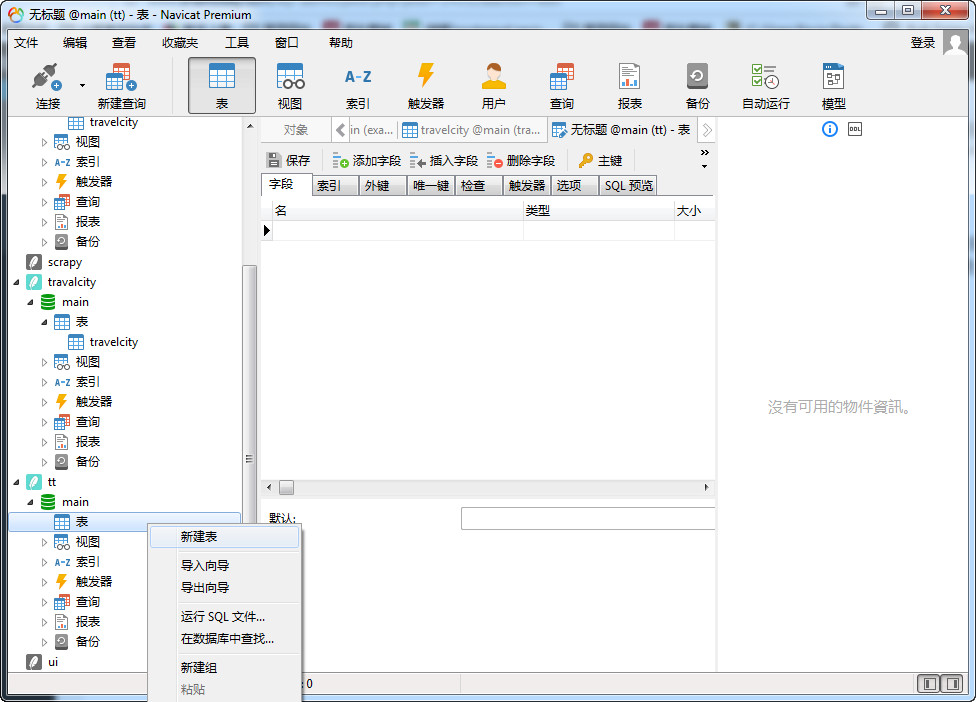
这里完成各种字段的设置之后,navicat会提示你输入表格的名称。另外,在这里可以选择的SQlite的数据类型只有4种,大大少于Mysql的数据类型。
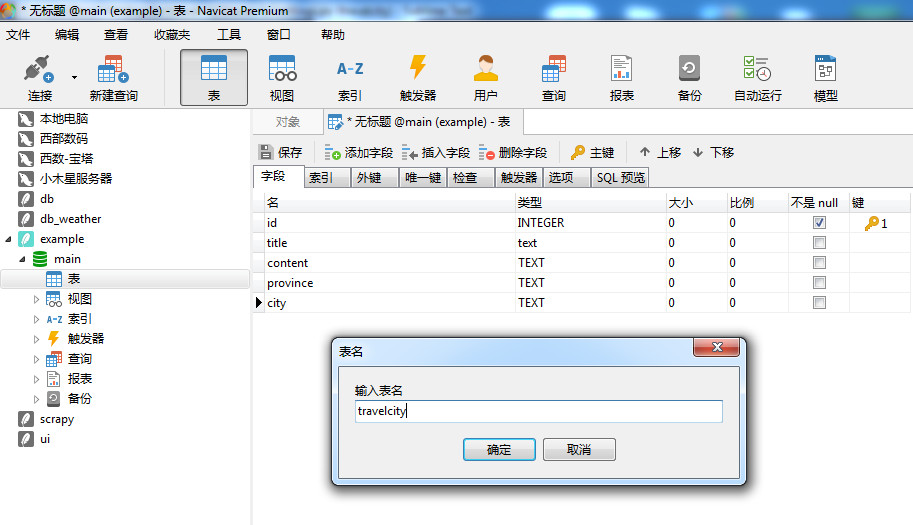
当然也可以通过命令来建立:
import sqlite3
# test.db is a file in the working directory
conn = sqlite3.connect("test.db")
c = conn.cursor()
# create tables
sql = '''create table student (id int primary key, name varchar(20), score int, sex varchar(10), age int)'''
c.execute(sql)
# save the changes
conn.commit()
# close the connection with the database
conn.close()
可以参考这里:https://www.cnblogs.com/lmei/p/5322502.html
2.修改pipeline
import sqlite3
class Sqlite3Pipeline(object):
def __init__(self, sqlite_file, sqlite_table):
self.sqlite_file = sqlite_file
self.sqlite_table = sqlite_table
@classmethod
def from_crawler(cls, crawler):
return cls(
sqlite_file = crawler.settings.get('SQLITE_FILE'), # 从 settings.py 提取
sqlite_table = crawler.settings.get('SQLITE_TABLE', 'items')
)
def open_spider(self, spider):
self.conn = sqlite3.connect(self.sqlite_file)
self.cur = self.conn.cursor()
def close_spider(self, spider):
self.conn.close()
def process_item(self, item, spider):
insert_sql = "insert into travelcity (title,content,province,city) values('{}','{}','{}','{}')".format(item['title'], item['desc'],item['province'],item['city'])
#insert_sql = "insert into {} (title,content,province,city) values('{}','{}','{}','{}')".format(self.sqlite_table,item['title'], item['desc'],item['province'],item['city'])
self.cur.execute(insert_sql)
self.conn.commit()
return item
3.修改settings.py文件
SQLITE_FILE = 'example.db'
SQLITE_TABLE = 'travelcity'
ITEM_PIPELINES = {
'travalcity.pipelines.Sqlite3Pipeline': 300,
}
这时再运行爬虫就可以了。
可以参考:https://blog.csdn.net/weixin_34217711/article/details/90226081
4.在Navicat查询数据库的行数
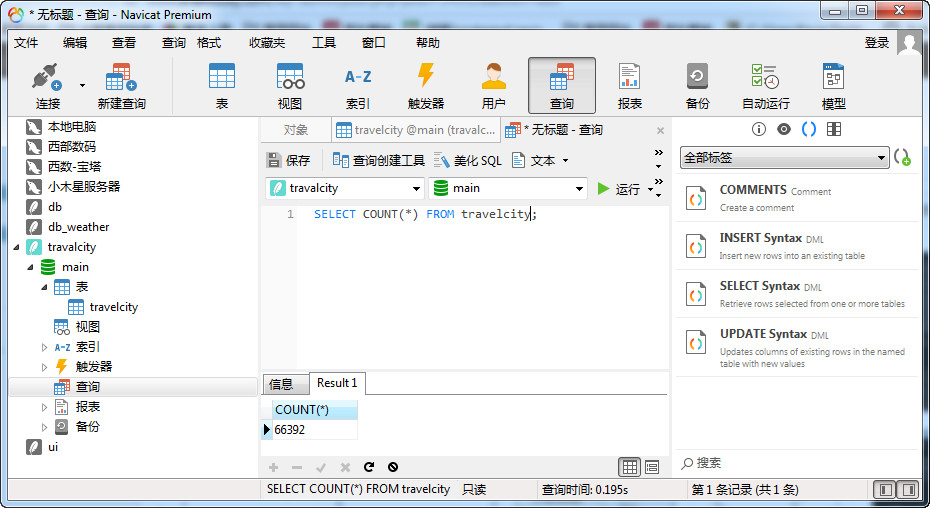
5.关于数据丢失的问题
查看scrapy的报表发现丢失了许多数据,一直搞不懂是什么原因。
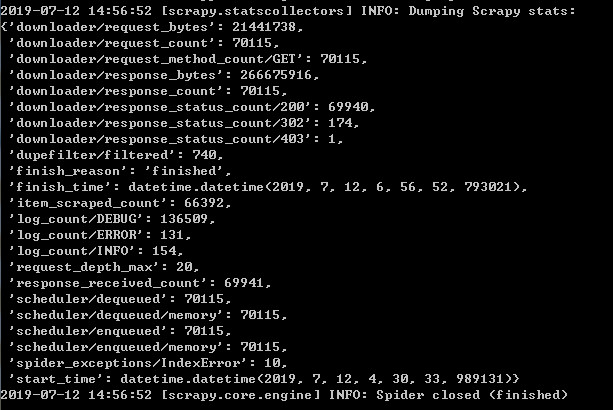
后来用两个列表页作测试,发现其中一个列表页丢失数据,加上twisted终于没有丢失数据了。
附最终代码:
import sqlite3
import pymysql.cursors
from scrapy import log
from twisted.enterprise import adbapi
class DbSqlitePipeline(object):
def __init__(self):
"""Initialize"""
self.__dbpool = adbapi.ConnectionPool('sqlite3',
database='example.db',
check_same_thread=False)
def shutdown(self):
"""Shutdown the connection pool"""
self.__dbpool.close()
def process_item(self,item,spider):
"""Process each item process_item"""
query = self.__dbpool.runInteraction(self.__insertdata, item, spider)
query.addErrback(self.handle_error)
return item
def __insertdata(self,tx,item,spider):
"""Insert data into the sqlite3 database"""
spidername=spider.name
tx.execute(\
"insert into worldcity(title,content,province,city) values (?,?,?,?)",(
item['title'],
item['desc'],
item['province'],
item['city'])
)
log.msg("Item stored in db", level=log.DEBUG)
def handle_error(self,e):
log.err(e)
参考:https://github.com/ritesh/sc/blob/master/scraper/pipelines.py
最终结果: