

一、抓取jobbole网站
1.scrapy调试
在项目根目录自己写一个main.py,调用命令行。
from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy","crawl","jobbole"])
并将settings.py中的robot设为False
Robotstext_obey = False
2.将列表页中的缩略图传递给request
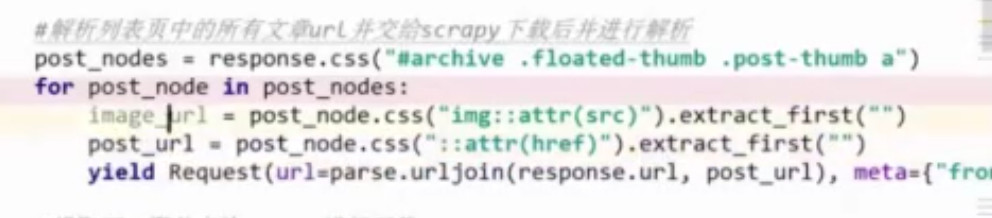
meta={"front_image_url":image_url},callback=...
用get取值,不会抛异常,最后面的表示默认为空:
![]()
3.下载图片
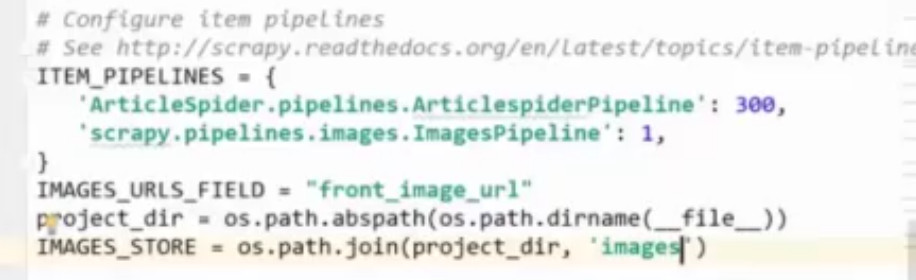
如果出现valueerror,则要将这里改为数组。

重写pipeline
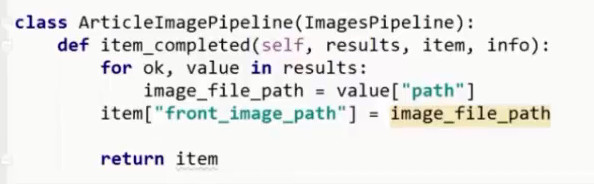
4.MD5
from Axxx.utils.common import get_md5
def get_md5(url):
if isinstance(url,str):
url = url.encode('utf-8')
m = hashlib.md5()
m.update(url)
return m.hexdigest()
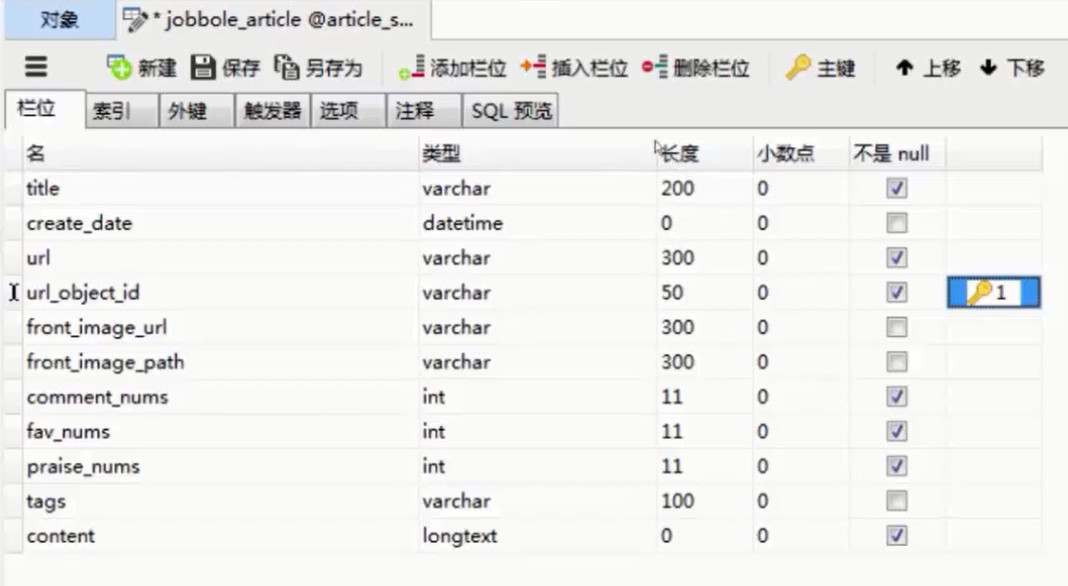
5.通过navicat添加字段
一定要设置一个主键:
6.将数据保存到Mysql
(1)同步机制
import MySQLdb
class MysqlPipeline(object):
#采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect('127.0.0.1', 'root', 'password', 'article_spider', charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
self.conn.commit()
然后再在settings.py中,将pipeline修改为这个。
(2)异步操作
seeting.py设置
MYSQL_HOST = "127.0.0.1" MYSQL_DBNAME = "article_spider" MYSQL_USER = "root" MYSQL_PASSWORD = "123456"
然后再写Pipline
import MySQLdb.cursors
from twisted.enterprise import adbapi
#连接池ConnectionPool
# def __init__(self, dbapiName, *connargs, **connkw):
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
#**dbparms-->("MySQLdb",host=settings['MYSQL_HOST']
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
7.直接写入django
https://github.com/scrapy-plugins/scrapy-djangoitem