

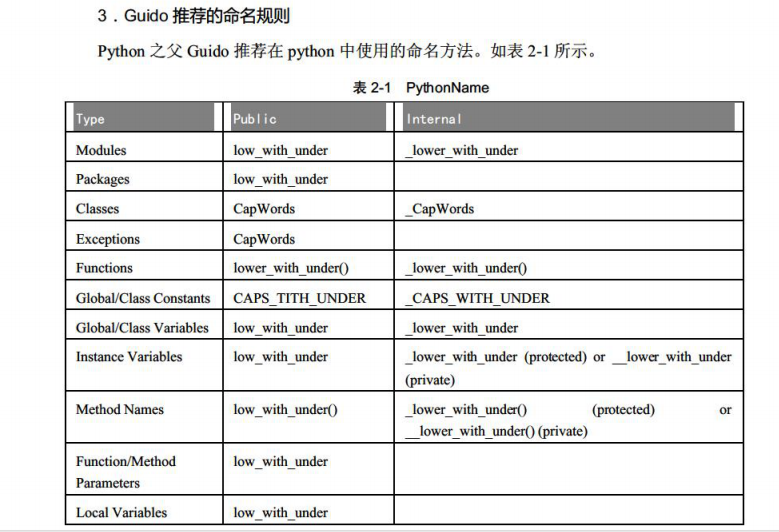
一、Python命名规则
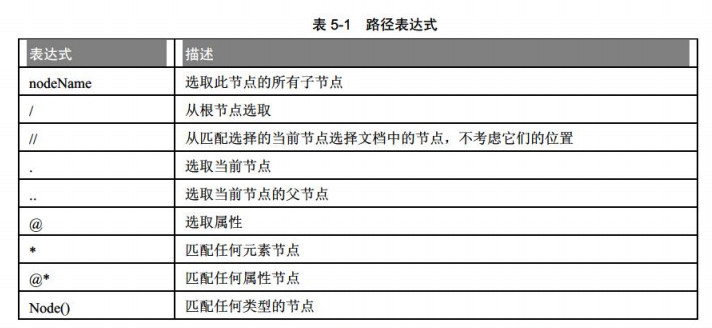
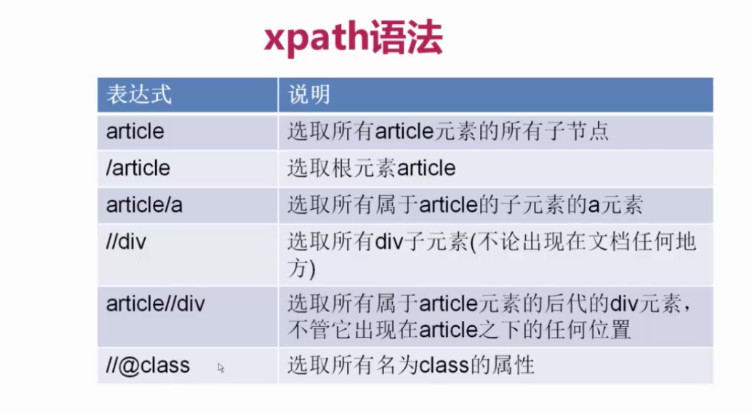
二、xpath用法:
这里的下标是从1开始的,不是0


抓取图片:
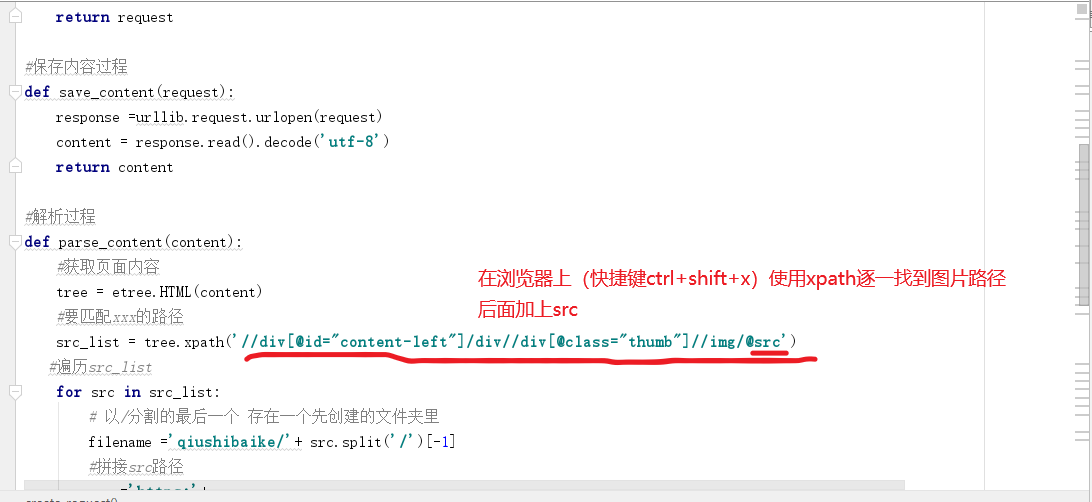
小技巧:
如果遇到]怎么办?
links = dom_tree.xpath("//a[@class='download']")#在xml中定位节点,返回的是一个列表
for index in range(len(links)):
# links[index]返回的是一个字典
if (index % 2) == 0:
print(links[index].tag)
print(links[index].attrib)
print(links[index].text)
比如url为磁力链接
那么
print(links[index].tag)#获取a标签名a
print(links[index].attrib)#获取a标签的属性href和class
print(links[index].text)#获取a标签的文字部分
的结果分别为:
a
{'href': 'magnet:?xt=urn:btih:7502edea0dfe9c2774f95118db3208a108fe10ca', 'class': 'download'}
磁力链接
参考:https://www.cnblogs.com/z-x-y/p/8260213.html
截取超级链接
//a[@class="text--link"]/@href //span[@class='l fl']/a/@href #截取超级链接
截取多个标签
比如,文章的正文部分又有h2,又有h3,又有p标签,可以通过下面的方法截取,不过我试了一下,发现它先将所有的h2,找出来,再将所有的p标签找出来排列,那么和原文章的顺序就乱了。。
所以最后还是要用正则。
xpath('//*[@id="xxx"]/h2|*[@id="xxx"]/h3|*[@id="xxx"]/p')
特殊的字段
ip.xpath('string(td[5])')[0].extract().strip() #获取第5个单元格的所有文本。
ip.xpath('td[8]/div[@class="bar"]/@title').re('\d{0,2}\.\d{0,}')[0] #匹配<div class="bar" title="0.0885秒"> 中的数字
如果图片url在不同的存储位置,xpath的时候用“|”符号。

常见问题:
(1)如果在chrome的xpath插件中可以用q_urls = response.xpath('//div[@class="line content"]')看到取值,但是在代码中取不到值,需要用下面的代码:
def get_detail(url):
html = requests.get(url,headers = headers)
response = etree.HTML(html.content)
q_urls = response.xpath('//div[@class="line content"]')
result = q_urls[0].xpath('string(.)').strip()
return result
(2)查看元素
content = selector.xpath('//div[@class="metarial"]')[0]
参考:
https://www.cnblogs.com/just-do/p/9778941.html
(3)乱码问题
如果用xpath取到的中文乱码,可以用下面的方案:
content=etree.tostring(content,encoding="utf-8").decode('utf-8')
参考:
https://www.cnblogs.com/Rhythm-/p/11374832.html
第五章 scrapy爬虫框架
1. __init__.py文件,它是个空文件,作用是将它的上级目录变成了一个模块,,可以供python导入使用。
2. items.py决定抓取哪些项目,wuhanmoviespider.py决定怎么爬的,settings.py决定由谁去处理爬取的内容,pipilines.py决定爬取后的内容怎么样处理。
3.
<h3>武汉<font color="#0066cc">今天</font>天气</h3>
选择方式为:.h3//text()而不是.h3/text()
4.使用json输出
settings.py中的Item_pipeline项,它是一个字典,字典是可以添加元素的,因此完全可以自行构造一个Python文件,然后加进去。
(1)创建pipelines2json.py文件
import time
import json
import codecs
class WeatherPipeline(object):
def process_item(self, item, spider):
today=time.strftime(‘%Y%m%d‘,time.localtime())
fileName=today+‘.json‘
with codecs.open(fileName,‘a‘,encoding=‘utf8‘) as fp:
line=json.dumps(dict(item),ensure_ascii=False)+‘\n‘
fp.write(line)
return item
(2)修改settings.py,将pipeline2json加入到Item_pipelines中去
Item_pipelines = {
'weather.pipelines.weatherpipeline':1,
'weather.将pipelines2json.weatherpipeline':2,
}
5.登陆数据库,数据表的命令
其实之前在这里已经学过了。不过那里是直接修改pipeline,这里新建了一个pipelines2mysql.py用来入库。
这里主要是为了标记一下数据库操作命令。
# 创建数据库:scrapyDB ,以utf8位编码格式,每条语句以’;‘结尾 CREATE DATABASE scrapyDB CHARACTER SET 'utf8' COLLATE 'utf8_general-Ci'; # 选中刚才创建的表: use scrapyDB; # 创建我们需要的字段:字段要和我们代码里一一对应,方便我们一会写sql语句 CREATE TABLE weather( id INT AUTO_INCREMENT, date char(24), week char(24), img char(128), temperature char(24), weather char(24), wind char(24), PRIMARY KEY(id) )ENGINE=InnoDB DEFAULT CHARSET='utf8';
查看一下weather表格的样子
show columns from weather 或者:desc weather
6.添加一个User_agent
在scrapy中的确是有默认的headers,但这个headrs与浏览器的headers是有区别的。有的网站会检查headers,所以需要给scrapy一个浏览器的headers。
当然还可以用下面的方法:
from getProxy import userAgents
BOT_NAME='getProxy'
SPIDER_MODULES=['getProxy.spiders']
NEWSPIDER_MODULE='getProxy.spiders'
USER_AGENT=userAgents.pcUserAgent.get('Firefox 4.0.1 – Windows')
ITEM_PIPELINES={'getProxy.pipelines.GetProxyPipeline':300}
只需要在settings.py里添加一个User_agent项就可以了。
这里修改了USER_AGENT,导入userAgents模块,下面给出userAgents模块代码:
pcUserAgent = {
"safari 5.1 – MAC":"User-Agent:Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"safari 5.1 – Windows":"User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"IE 9.0":"User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0);",
"IE 8.0":"User-Agent:Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"IE 7.0":"User-Agent:Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"IE 6.0":"User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Firefox 4.0.1 – MAC":"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Firefox 4.0.1 – Windows":"User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera 11.11 – MAC":"User-Agent:Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera 11.11 – Windows":"User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Chrome 17.0 – MAC":"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Maxthon":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Tencent TT":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"The World 2.x":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"The World 3.x":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"sogou 1.x":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"360":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Avant":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Green Browser":"User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"
}
mobileUserAgent = {
"iOS 4.33 – iPhone":"User-Agent:Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"iOS 4.33 – iPod Touch":"User-Agent:Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"iOS 4.33 – iPad":"User-Agent:Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Android N1":"User-Agent: Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Android QQ":"User-Agent: MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Android Opera ":"User-Agent: Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Android Pad Moto Xoom":"User-Agent: Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"BlackBerry":"User-Agent: Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"WebOS HP Touchpad":"User-Agent: Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Nokia N97":"User-Agent: Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Windows Phone Mango":"User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UC":"User-Agent: UCWEB7.0.2.37/28/999",
"UC standard":"User-Agent: NOKIA5700/ UCWEB7.0.2.37/28/999",
"UCOpenwave":"User-Agent: Openwave/ UCWEB7.0.2.37/28/999",
"UC Opera":"User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999"
}
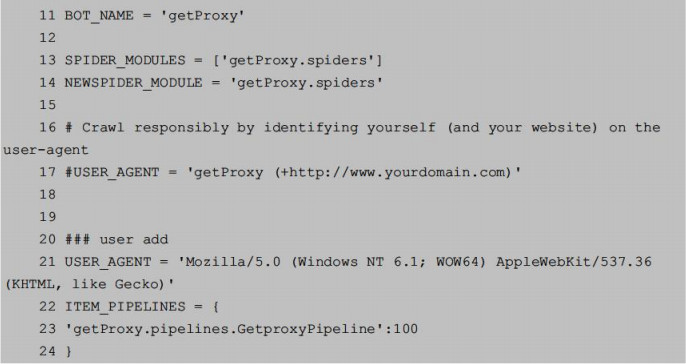
7.封锁user-agent破解
方法其实很简单:
(1).新建一个middlewares目录,创建__init__.py,以及资源文件resource.py和中间件文件customUserAgent.py。
(2).编辑customUserAgent.py,将资源文件resource.py中的user-agent随机选择一个出来,作为Scrapy的user-agent。
(3)修改settings.py文件,将RandomUserAgent加入DOWNLOADER_MIDDLEWARES
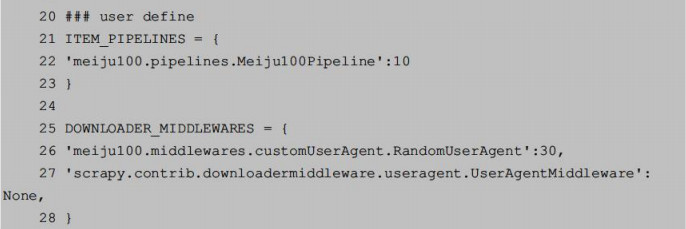
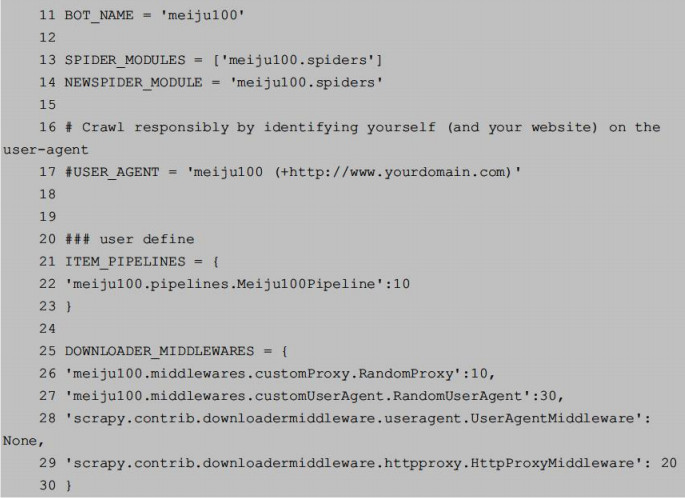
8.封锁IP破解
方法和上面差不多:
(1)在resource.py中添加PROXIES。
(2)创建customProxy.py,让Scrapy爬取网站时随机使用IP池中的代理。
(3)修改settings.py文件。
可以参考:https://www.cnblogs.com/hqutcy/p/7341212.html
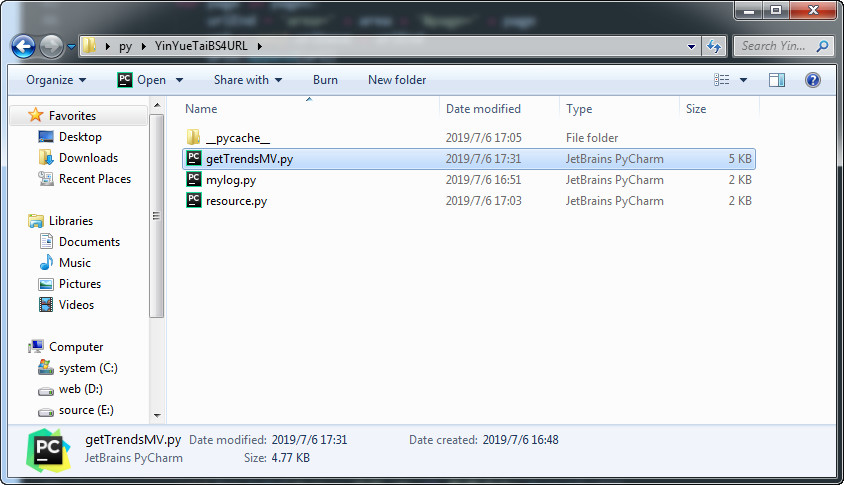
第六章 自写爬虫模板
项目文件图示:
代码:
getTrendsMV.py
from bs4 import BeautifulSoup
import urllib.request
import time
from mylog import MyLog as mylog
import resource
import random
class Item(object):
top_num = None # 排名
score = None # 打分
mvname = None # mv名字
singer = None # 演唱者
releasetime = None # 发布时间
class GetMvList(object):
""" the all data from www.yinyuetai.com
所有的数据都来自www.yinyuetai.com
"""
def __init__(self):
self.urlbase = 'http://vchart.yinyuetai.com/vchart/trends?'
self.areasDic = {
'ALL': '总榜',
'ML': '内地篇',
'HT': '港台篇',
'US': '欧美篇',
'KR': '韩国篇',
'JP': '日本篇',
}
self.log = mylog()
self.geturls()
def geturls(self):
# 获取url池
areas = [i for i in self.areasDic.keys()]
pages = [str(i) for i in range(1, 4)]
for area in areas:
urls = []
for page in pages:
urlEnd = 'area=' + area + '&page=' + page
url = self.urlbase + urlEnd
urls.append(url)
self.log.info('添加URL:{}到URLS'.format(url))
self.spider(area, urls)
def getResponseContent(self, url):
"""从页面返回数据"""
fakeHeaders = {"User-Agent": self.getRandomHeaders()}
request = urllib.request.Request(url, headers=fakeHeaders)
proxy = urllib.request.ProxyHandler({'http': 'http://' + self.getRandomProxy()})
opener = urllib.request.build_opener(proxy)
urllib.request.install_opener(opener)
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf8')
time.sleep(1)
except Exception as e:
self.log.error('Python 返回 URL:{} 数据失败'.format(url))
return ''
else:
self.log.info('Python 返回 URL:{} 数据成功'.format(url))
return html
def getRandomProxy(self):
# 随机选取Proxy代理地址
return random.choice(resource.PROXIES)
def getRandomHeaders(self):
# 随机选取User-Agent头
return random.choice(resource.UserAgents)
def spider(self, area, urls):
items = []
for url in urls:
responseContent = self.getResponseContent(url)
if not responseContent:
continue
soup = BeautifulSoup(responseContent, 'lxml')
tags = soup.find_all('li', attrs={'name': 'dmvLi'})
for tag in tags:
item = Item()
item.top_num = tag.find('div', attrs={'class': 'top_num'}).get_text()
if tag.find('h3', attrs={'class': 'desc_score'}):
item.score = tag.find('h3', attrs={'class': 'desc_score'}).get_text()
else:
item.score = tag.find('h3', attrs={'class': 'asc_score'}).get_text()
item.mvname = tag.find('a', attrs={'class': 'mvname'}).get_text()
item.singer = tag.find('a', attrs={'class': 'special'}).get_text()
item.releasetime = tag.find('p', attrs={'class': 'c9'}).get_text()
items.append(item)
self.log.info('添加mvName为{}的数据成功'.format(item.mvname))
self.pipelines(items, area)
def pipelines(self, items, area):
filename = '音悦台V榜-榜单.txt'
nowtime = time.strftime('%Y-%m-%d %H:%M:S', time.localtime())
with open(filename, 'a', encoding='utf8') as f:
f.write('{} --------- {}\r\n'.format(self.areasDic.get(area), nowtime))
for item in items:
f.write("{} {} \t {} \t {} \t {}\r\n".format(item.top_num,
item.score,
item.releasetime,
item.mvname,
item.singer
))
self.log.info('添加mvname为{}的MV到{}...'.format(item.mvname, filename))
f.write('\r\n'*4)
if __name__ == '__main__':
GetMvList()
mylog.py
#!/usr/bin/env python
# coding: utf-8
import logging
import getpass
import sys
# 定义MyLog类
class MyLog(object):
def __init__(self):
self.user = getpass.getuser() # 获取用户
self.logger = logging.getLogger(self.user)
self.logger.setLevel(logging.DEBUG)
# 日志文件名
self.logfile = sys.argv[0][0:-3] + '.log' # 动态获取调用文件的名字
self.formatter = logging.Formatter('%(asctime)-12s %(levelname)-8s %(message)-12s\r\n')
# 日志显示到屏幕上并输出到日志文件内
self.logHand = logging.FileHandler(self.logfile, encoding='utf-8')
self.logHand.setFormatter(self.formatter)
self.logHand.setLevel(logging.DEBUG)
self.logHandSt = logging.StreamHandler()
self.logHandSt.setFormatter(self.formatter)
self.logHandSt.setLevel(logging.DEBUG)
self.logger.addHandler(self.logHand)
self.logger.addHandler(self.logHandSt)
# 日志的5个级别对应以下的5个函数
def debug(self, msg):
self.logger.debug(msg)
def info(self, msg):
self.logger.info(msg)
def warn(self, msg):
self.logger.warn(msg)
def error(self, msg):
self.logger.error(msg)
def critical(self, msg):
self.logger.critical(msg)
if __name__ == '__main__':
mylog = MyLog()
mylog.debug(u"I'm debug 中文测试")
mylog.info(u"I'm info 中文测试")
mylog.warn(u"I'm warn 中文测试")
mylog.error(u"I'm error 中文测试")
mylog.critical(u"I'm critical 中文测试")
resource.py
#!/usr/bin/env python
# coding: utf-8
UserAgents = [
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
]
# 代理ip地址,如果不能使用,去网上找几个免费的使用
# 这里使用的都是http
PROXIES = [
"120.83.102.255:808",
"111.177.106.196:9999",
]