

Q:有个疑问就是,模型本身不是线性的,为什么一定要先用线性模型做?
A:有核函数和泰勒展开等等,可以无限逼近转化成线性?
小知识:
1.Sigmoid函数,即f(x)=1/(1+e-x)。是神经元的非线性作用函数。广泛应用在神经网络中。又叫Logistic函数。
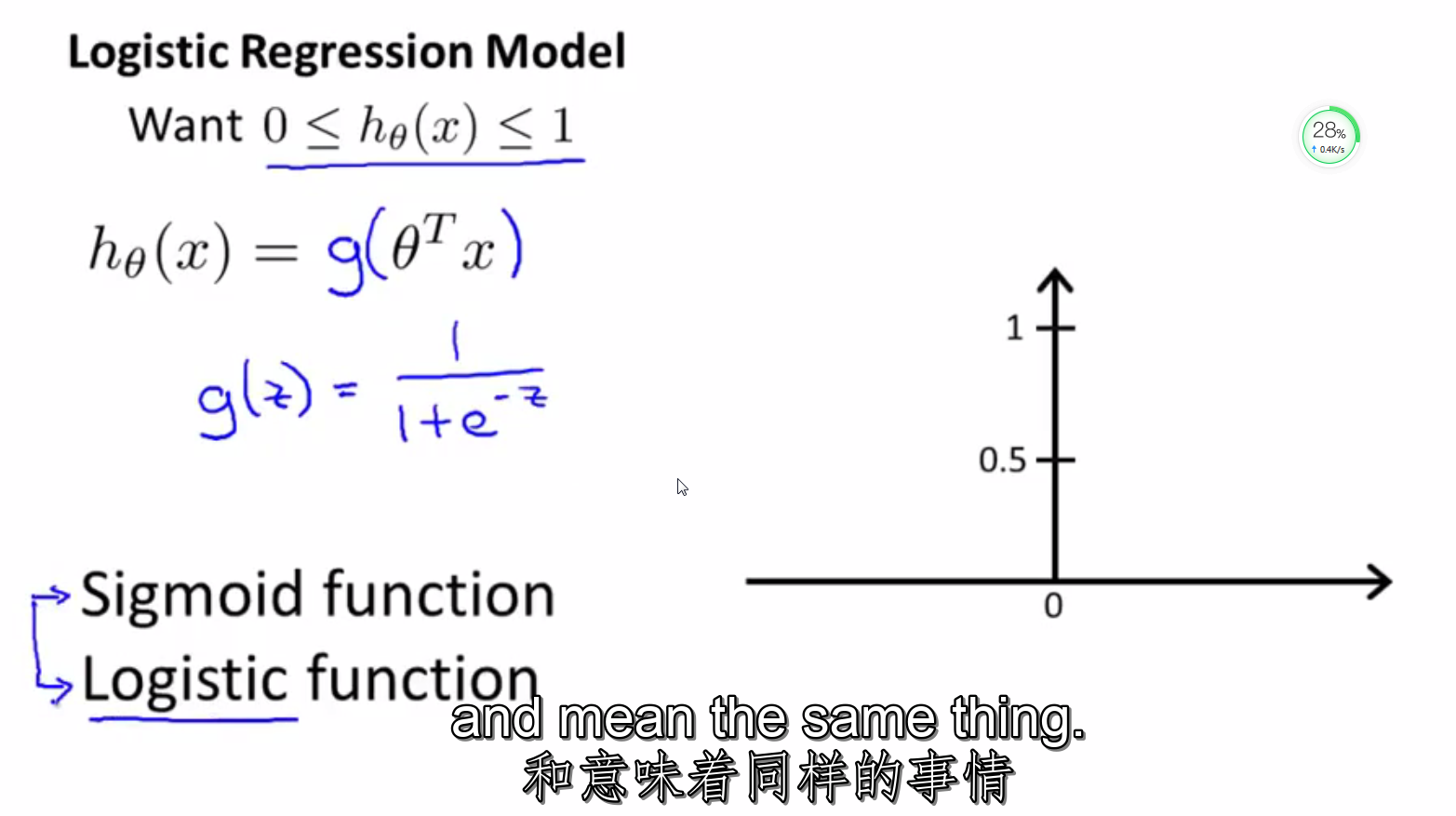
机器学习中一个重要的预测模型逻辑回归(LR)就是基于Sigmoid函数实现的。LR模型的主要任务是给定一些历史的{X,Y},其中X是样本n个特征值,Y的取值是{0,1}代表正例与负例,通过对这些历史样本的学习,从而得到一个数学模型,给定一个新的X,能够预测出Y。LR模型是一个二分类模型,即对于一个X,预测其发生或不发生。但事实上,对于一个事件发生的情况,往往不能得到100%的预测,因此LR可以得到一个事件发生的可能性,超过50%则认为事件发生,低于50%则认为事件不发生。
可参考:https://blog.csdn.net/su_mo/article/details/79281623
http://www.mamicode.com/info-detail-2315826.html
https://www.cnblogs.com/xitingxie/p/9924523.html
2.RBF– 径向基核函数 (Radial Basis Function)
Radical: adj. 放射状的; 辐射状的
Gaussian函数还有另外一个叫法——径向基函数。
就是某种沿径向对称的标量函数。 通常定义为空间中任一点x到某一中心xc之间欧氏距离的单调函数 , 可记作 k(||x-xc||), 其作用往往是局部的 , 即当x远离xc时函数取值很小。
可以参考:https://www.cnblogs.com/hxsyl/p/5231389.html
一、什么是核函数?
我来举一个核函数把低维空间映射到高维空间的例子。下面这张图位于第一、二象限内。我们关注红色的门,以及“北京四合院”这几个字下面的紫色的字母。我们把红色的门上的点看成是“+”数据,紫色字母上的点看成是“-”数据,它们的横、纵坐标是两个特征。显然,在这个二维空间内,“+”“-”两类数据不是线性可分的。
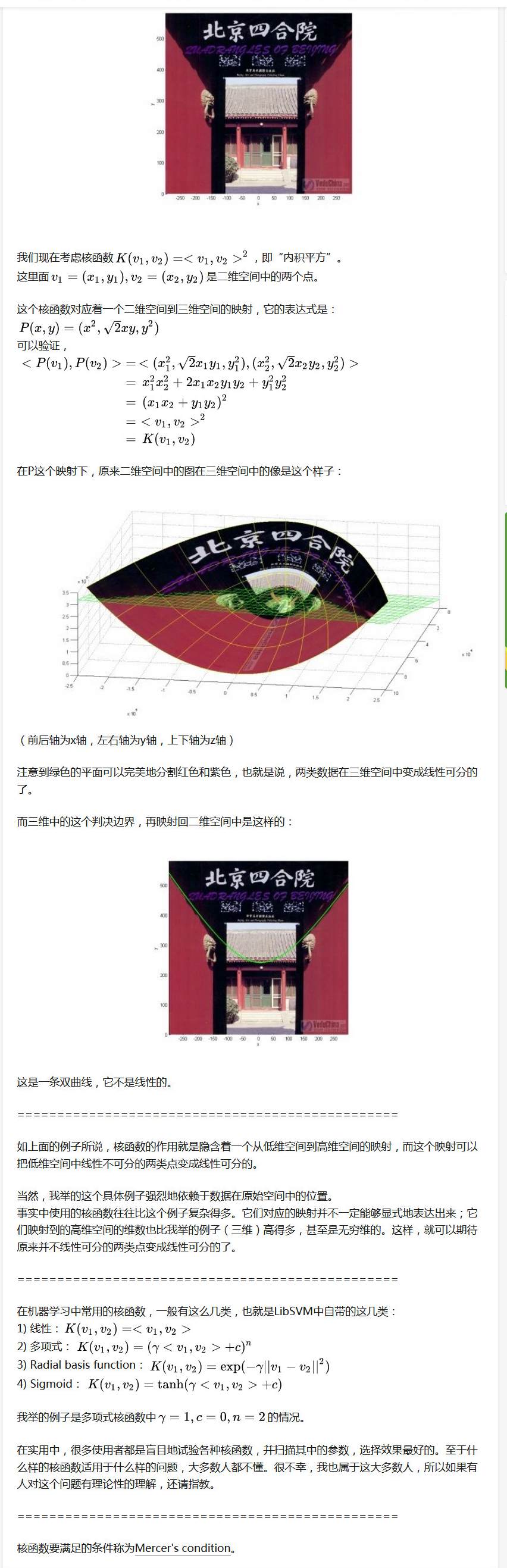
由于我以应用SVM为主,对它的理论并不很了解,就不阐述什么了。
使用SVM的很多人甚至都不知道这个条件,也不关心它;有些不满足该条件的函数也被拿来当核函数用。
作者:王赟 Maigo
链接:https://www.zhihu.com/question/24627666/answer/28440943
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
可参考:https://blog.csdn.net/robin_xu_shuai/article/details/76946333
二、相关实践
1.使用SVR(支持向量回归机)的RBF(高斯核函数)拟合预测股票
(1)成果
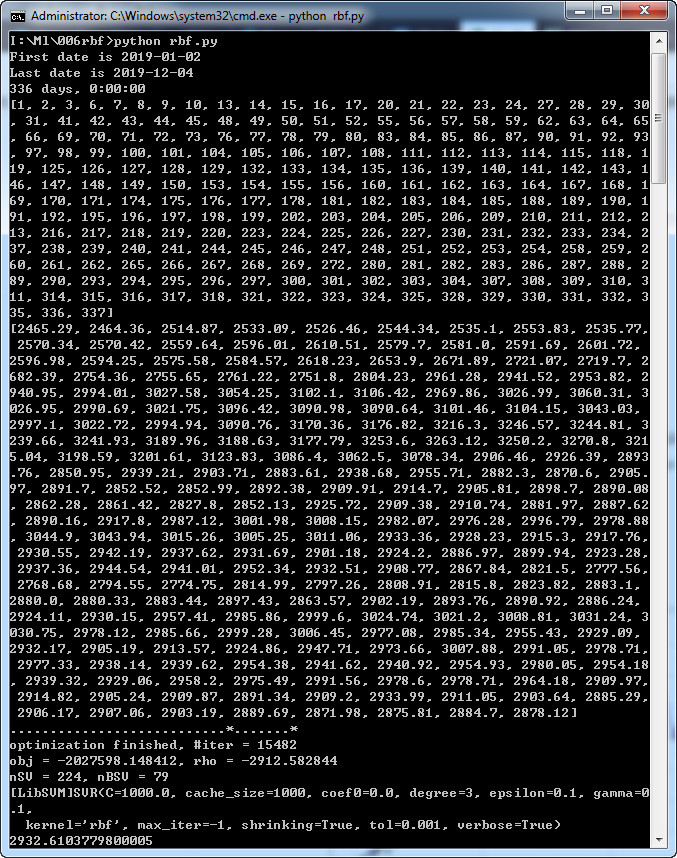
拟合效果
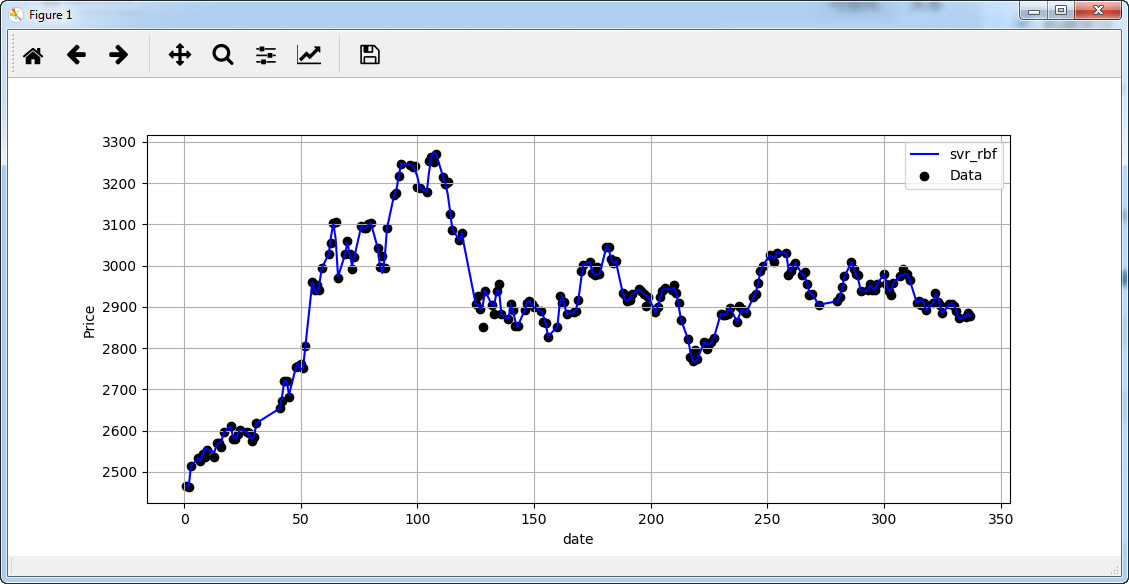
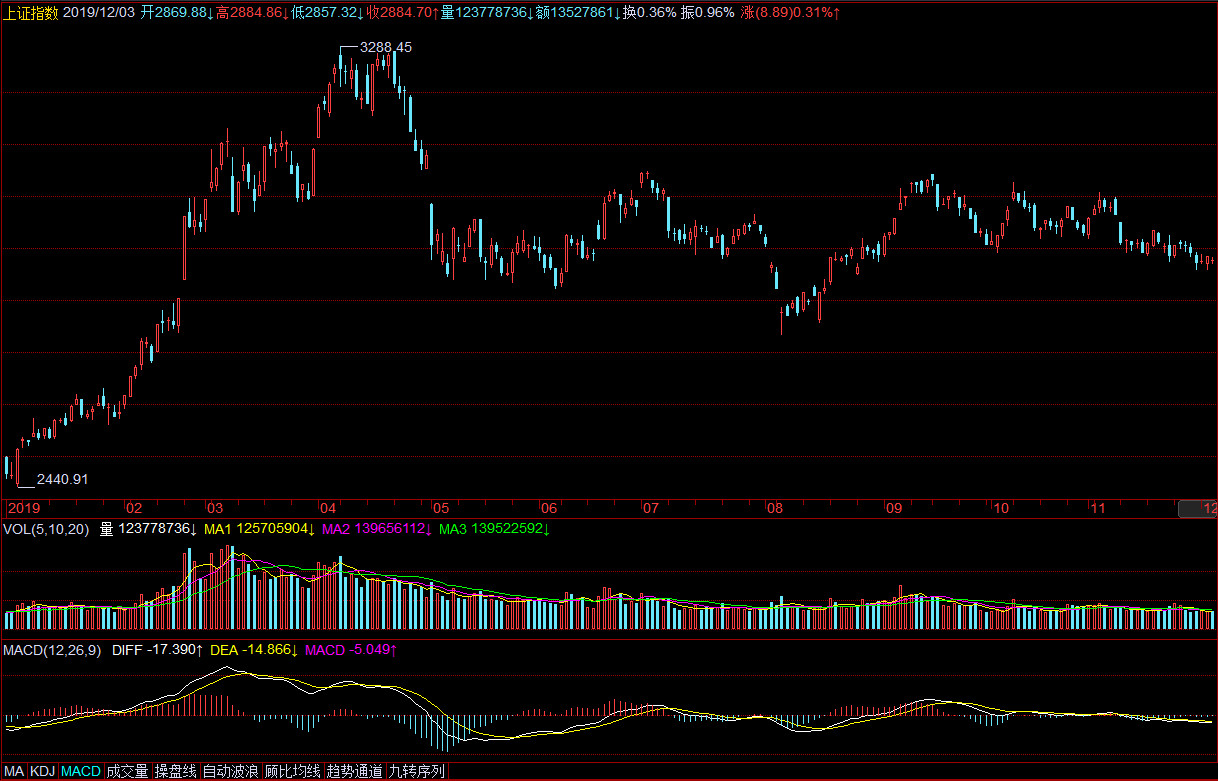
(2)实际走势
(3)代码
import os
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
from datetime import datetime as dt
from sklearn import preprocessing
from sklearn.svm import SVC, SVR
import plotly.offline as of
import plotly.graph_objs as go
import tushare as ts
# pip install ciso8601
# pip install stockai
def get_stock_data(stock_num, start):
"""
下载数据
股票数据的特征
date:日期
open:开盘价
high:最高价
close:收盘价
low:最低价
volume:成交量
price_change:价格变动
p_change:涨跌幅
ma5:5日均价
ma10:10日均价
ma20:20日均价
v_ma5:5日均量
v_ma10:10日均量
v_ma20:20日均量
:param stock_num:
:return:df
"""
df = ts.get_hist_data(stock_num, start=start, ktype='D')
return df
def draw_kchart(df, filename):
"""
画k线图
"""
Min_date = df.index.min()
Max_date = df.index.max()
print("First date is", Min_date)
print("Last date is", Max_date)
interval_date = dt.strptime(Max_date, "%Y-%m-%d") - dt.strptime(Min_date, "%Y-%m-%d")
print(interval_date)
trace = go.Ohlc(x=df.index, open=df['open'], high=df['high'], low=df['low'], close=df['close'])
data = [trace]
of.plot(data, filename=filename)
def stock_etl(df):
df.dropna(axis=0, inplace=True)
# print(df.isna().sum())
df.sort_values(by=['date'], inplace=True, ascending=True)
return df
def get_data(df):
data = df.copy()
# 年,月,天
# data['date'] = data.index.str.split('-').str[2]
# data['date'] = data.index.str.replace('-','')
# print(data.index.tolist())
data['date'] = [(dt.strptime(x, '%Y-%m-%d') - dt.strptime('2019-01-01', '%Y-%m-%d')).days for x in data.index.tolist()]
data['date'] = pd.to_numeric(data['date'])
return [data['date'].tolist(), data['close'].tolist()]
def predict_prices(dates, prices, x):
dates = np.reshape(dates, (len(dates), 1))
x = np.reshape(x, (len(x), 1))
svr_lin = SVR(kernel='linear', C=1e3,gamma=0.1, verbose=True, cache_size=1000)
svr_poly = SVR(kernel='poly', C=1e3, degree=2, gamma=0.1, verbose=True, cache_size=1000)
svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1, verbose=True, cache_size=1000)
plt.scatter(dates, prices, c='k', label='Data')
# 训练
# svr_lin.fit(dates, prices)
# print(svr_lin)
# print(svr_lin.predict(x)[0])
# plt.plot(dates, svr_lin.predict(dates), c='g', label='svr_lin')
# svr_poly.fit(dates, prices)
# print(svr_poly)
# print(svr_poly.predict(x)[0])
# plt.plot(dates, svr_lin.predict(dates), c='g', label='svr_lin')
svr_rbf.fit(dates, prices)
print(svr_rbf)
print(svr_rbf.predict(x)[0])
plt.plot(dates, svr_rbf.predict(dates), c='b', label='svr_rbf')
plt.xlabel('date')
plt.ylabel('Price')
plt.grid(True)
plt.legend()
plt.show()
# return svr_lin.predict(x)[0], svr_poly.predict(x)[0], svr_rbf.predict(x)[0]
if __name__ == "__main__":
"""
预测股价和时间之间的关系
"""
# sh 获取上证指数k线数据
# sz 获取深圳成指k线数据
# cyb 获取创业板指数k线数据
df = get_stock_data('sh', '2019-01-01')
# + 张家港行
# df = get_stock_data('002839', '2019-01-01')
df = stock_etl(df)
curPath = os.path.abspath(os.path.dirname(__file__))
draw_kchart(df, curPath + '/simple_ohlc.html')
dates, prices = get_data(df)
print(dates)
print(prices)
# print(predict_prices(dates, prices, [31]))
# print(predict_prices(dates, prices, ['20190731']))
a = dt.strptime('2019-07-31', '%Y-%m-%d')
b = dt.strptime('2019-01-01', '%Y-%m-%d')
c = (a - b).days
predict_prices(dates, prices, )
参考:http://www.pythonheidong.com/blog/article/53122/
2.其他
http://www.sohu.com/a/123306028_505915