

一、简单介绍
二、知识点
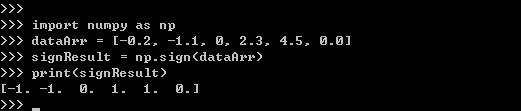
1.np.sign
2.iloc[:,:-1]
提取所有行,而后提取除最后一列之外的所有列。
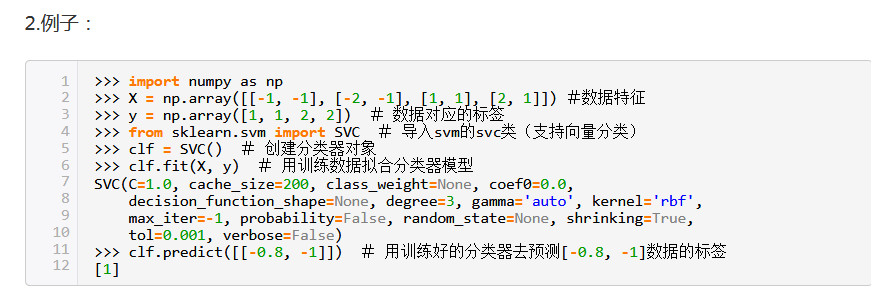
3.clf.fit(x,y)
比如下面代码中的train_df.iloc[:,-1:]就是label那一列。
4. sklearn 保存模型
经实测可用

from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
import pickle #pickle模块
#保存Model(注:save文件夹要预先建立,否则会报错)
with open('clf.pickle', 'wb') as f:
pickle.dump(clf, f)
#读取Model
with open('clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
#测试读取后的Model
print(clf2.predict(X[0:1]))
参考:https://www.cnblogs.com/Allen-rg/p/9548539.html
实际调用:
# 随机深林训练 导入包
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, precision_score, confusion_matrix, recall_score, accuracy_score
# 训练模型
clf = RandomForestClassifier(n_estimators=65, max_features="auto",max_depth=30,min_samples_split=200)
with open('clf02.pickle', 'rb') as f:
clf = pickle.load(f)
#测试读取后的Model
# 模型调用
pre_train = clf.predict(train_df.iloc[:,:-1])
# print("在训练集预测的结果为:",pre_train)
print("在训练集的accuracy_score为:",accuracy_score(pre_train,train_df.iloc[:,-1:]))
2.KDJ指标
def stochastic_oscillator_d(df, n):
#这个指标返回的是ohlc,volume,SOK值的df
SOK = [0]
for i in range(n, len(df)):
high = df.loc[(i-n):i, 'high']
# 截取最高价中的一段
low = df.loc[(i-n):i, 'low']
SOK.append((df.loc[i, 'close'] - min(low)) / (max(high) - min(low)))
# 计算出K值
SOK = pd.Series(SOK, name='SOK')
df = df.join(SOK)
return df
3.威廉指数
这个和上面的差不多,只不过分母变成了n日最高价-最新的收盘价。
计算出的指数值在0至100之间波动,不同的是,威廉指数的值越小,市场的买气越重,反之,其值越大,市场卖气越浓。
当%R线达到80时,市场处于超卖状况,股价走势随时可能见底。因此,80的横线一般称为买进线,投资者在此可以伺机买入;相反,当%R线达到20时,市场处于超买状况,走势可能即将见顶,20的横线被称为卖出线。
4.diff
M = df['close'].diff(3-1)
就表示用第3个close减去第1个close,用第4个减去第2个。
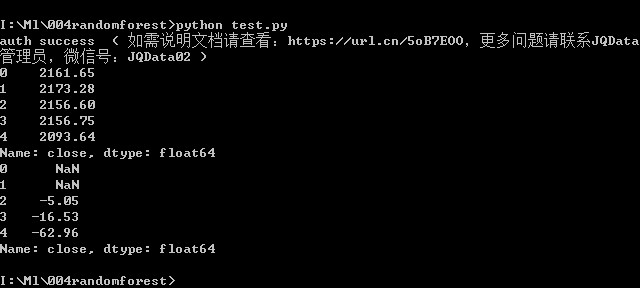
5.df.shift(2)
表示向后移2
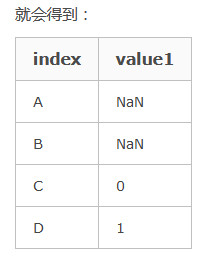
6.accuracy_score
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数。
>>>import numpy as np >>>from sklearn.metrics import accuracy_score >>>y_pred = [0, 2, 1, 3] >>>y_true = [0, 1, 2, 3] >>>accuracy_score(y_true, y_pred) 0.5 >>>accuracy_score(y_true, y_pred, normalize=False) 2
7.pandas ewm
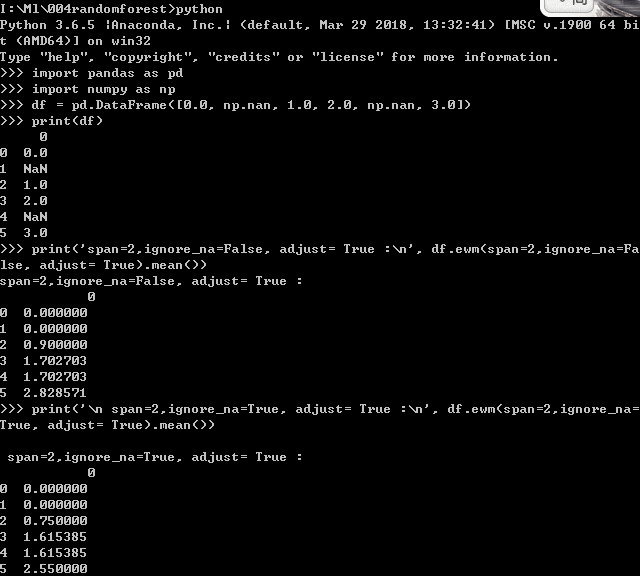
可以参考:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.ewm.html
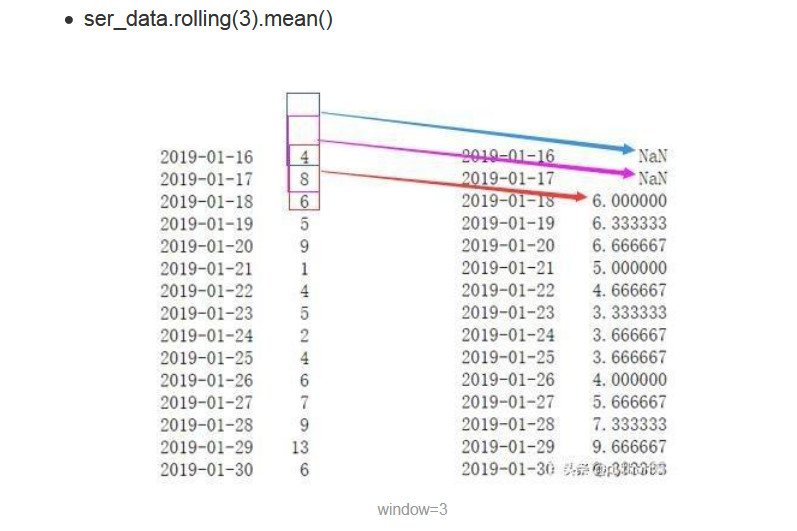
8.pandas.rolling
pandas中提供了pandas.DataFrame.rolling这个函数来实现滑动窗口值计算,下面是这个函数的原型:
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None),参数含义如下图:

8.RSI
N日RSI =N日内收盘涨幅的平均值/(N日内收盘涨幅均值+N日内收盘跌幅均值) ×100
def relative_strength_index(df, n):
i = 0
UpI = [0]
DoI = [0]
while i + 1 <= df.index[-1]:
UpMove = df.loc[i + 1, 'high'] - df.loc[i, 'high']
DoMove = df.loc[i, 'low'] - df.loc[i + 1, 'low']
if UpMove > DoMove and UpMove > 0:
UpD = UpMove
else:
UpD = 0
UpI.append(UpD)
if DoMove > UpMove and DoMove > 0:
DoD = DoMove
else:
DoD = 0
DoI.append(DoD)
i = i + 1
UpI = pd.Series(UpI)
DoI = pd.Series(DoI)
print(UpI.head(10))
print(DoI.head(10))
PosDI = pd.Series(UpI.ewm(span=n, min_periods=n).mean())
NegDI = pd.Series(DoI.ewm(span=n, min_periods=n).mean())
print(PosDI)
RSI = pd.Series(PosDI / (PosDI + NegDI), name='RSI_' + str(n))
df = df.join(RSI)
return df
10. OBV
以某日为基期,逐日累计每日上市股票总成交量,若隔日指数或股票上涨,则基期OBV加上本日成交量为本日OBV。隔日指数或股票下跌,则基期OBV减去本日成交量为本日OBV。一般来说,只是观察OBV的升降并无多大意义,必须配合K线图的走势才有实际的效用。
代码
def on_balance_volume(df, n):
i = 0
OBV = [0]
while i < df.index[-1]:
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] > 0:
OBV.append(df.loc[i + 1, 'volume'])
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] == 0:
OBV.append(0)
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] < 0:
OBV.append(-df.loc[i + 1, 'volume'])
i = i + 1
OBV = pd.Series(OBV)
print(OBV.head())
OBV_ma = pd.Series(OBV.rolling(n, min_periods=n).mean(), name='OBV_' + str(n))
df = df.join(OBV_ma)
return df
11.clf
print(clf)打印的内容如下:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=30, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=200,
min_weight_fraction_leaf=0.0, n_estimators=65, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
二、成果展示
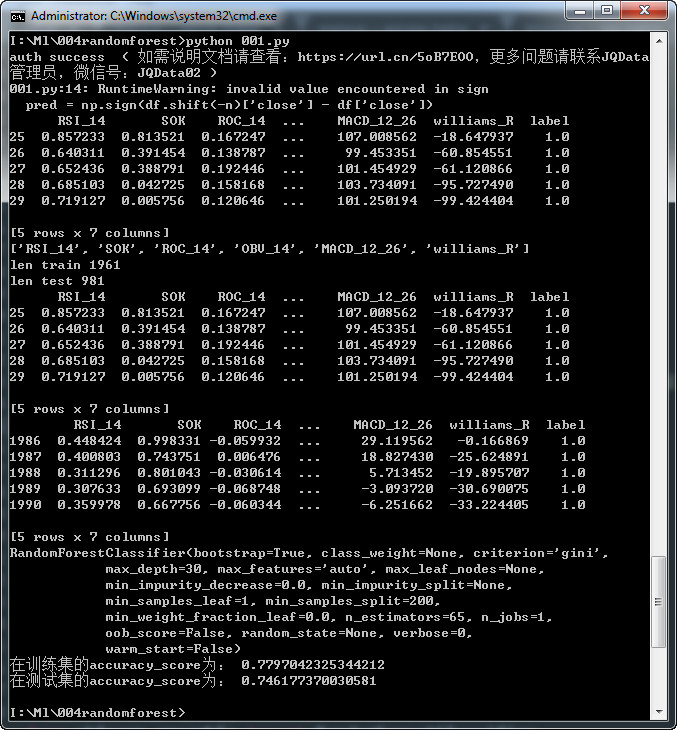
三、代码
# 导入模块
import numpy as np
import pandas as pd
from jqdatasdk import *
auth('138xxxxxxxx','asdf1234')
data = get_price("000001.XSHG",count=3000,end_date="2019-04-03",fields=["open","close","high","low","volume"])
# print(data.head(5))
datas = data.reset_index(drop=True)
datas.head(5)
# # 获取预测的标签 这里n为10 也就是预测10天后的涨跌标签
#这个函数的作用就是将10天后的价格前移10天,与当前价格比较,得到一个数值,根据这个数值的正、负,生成1、-1的结果。
def compute_prediction_int(df, n):
pred = np.sign(df.shift(-n)['close'] - df['close'])
pred = pred.iloc[:-n]
return pred.astype(int)
## 计算Stochastic Oscillator
def stochastic_oscillator_d(df, n):
SOK = [0]
for i in range(n, len(df)):
high = df.loc[(i-n):i, 'high']
low = df.loc[(i-n):i, 'low']
SOK.append((df.loc[i, 'close'] - min(low)) / (max(high) - min(low)))
SOK = pd.Series(SOK, name='SOK')
df = df.join(SOK)
return df
## 计算Williams %R
def williams_R(df, n):
R = [0]
for i in range(n, len(df)):
high = df.loc[(i-n):i, 'high']
low = df.loc[(i-n):i, 'low']
R.append((max(high) - df.loc[i, 'close']) / (max(high) - min(low))*(-100))
williams_R = pd.Series(R, name='williams_R')
df = df.join(williams_R)
return df
## 计算变化率
def rate_of_change(df, n):
M = df['close'].diff(n - 1)
N = df['close'].shift(n - 1)
ROC = pd.Series(M / N, name='ROC_' + str(n))
df = df.join(ROC)
return df
## 计算RSI
def relative_strength_index(df, n):
i = 0
UpI = [0]
DoI = [0]
while i + 1 <= df.index[-1]:
UpMove = df.loc[i + 1, 'high'] - df.loc[i, 'high']
DoMove = df.loc[i, 'low'] - df.loc[i + 1, 'low']
if UpMove > DoMove and UpMove > 0:
UpD = UpMove
else:
UpD = 0
UpI.append(UpD)
if DoMove > UpMove and DoMove > 0:
DoD = DoMove
else:
DoD = 0
DoI.append(DoD)
i = i + 1
UpI = pd.Series(UpI)
DoI = pd.Series(DoI)
PosDI = pd.Series(UpI.ewm(span=n, min_periods=n).mean())
NegDI = pd.Series(DoI.ewm(span=n, min_periods=n).mean())
RSI = pd.Series(PosDI / (PosDI + NegDI), name='RSI_' + str(n))
df = df.join(RSI)
return df
## 计算On Balance Volume
def on_balance_volume(df, n):
i = 0
OBV = [0]
while i < df.index[-1]:
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] > 0:
OBV.append(df.loc[i + 1, 'volume'])
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] == 0:
OBV.append(0)
if df.loc[i + 1, 'close'] - df.loc[i, 'close'] < 0:
OBV.append(-df.loc[i + 1, 'volume'])
i = i + 1
OBV = pd.Series(OBV)
OBV_ma = pd.Series(OBV.rolling(n, min_periods=n).mean(), name='OBV_' + str(n))
df = df.join(OBV_ma)
return df
## 计算MACD
def macd(df, n_fast, n_slow):
EMAfast = pd.Series(df['close'].ewm(span=n_fast, min_periods=n_slow).mean())
EMAslow = pd.Series(df['close'].ewm(span=n_slow, min_periods=n_slow).mean())
MACD = pd.Series(EMAfast - EMAslow, name='MACD_' + str(n_fast) + '_' + str(n_slow))
df = df.join(MACD)
return df
# 数据集准备,返回的是close+各项指标的df。
def feature_extraction(data):
data = relative_strength_index(data, n=14)
data = stochastic_oscillator_d(data, n=14)
data = rate_of_change(data, n=14)
data = on_balance_volume(data, n=14)
data = macd(data, 12, 26)
data = williams_R(data, n = 14)
del(data['open'])
del(data['high'])
del(data['low'])
del(data['volume'])
return data
def prepare_data(df, horizon):
data = feature_extraction(df).dropna().iloc[:-horizon]
data['label'] = compute_prediction_int(data, n=horizon)
del(data['close'])
return data.dropna()
# 数据和特征获取并合并
datas1 = prepare_data(datas, horizon=10)
#将除['gain', 'label']之外的columns提取出来
features = [x for x in datas1.columns if x not in ['gain', 'label']]
print(datas1.head(5))
print(features)
# 训练集和测试集 划分
train_size = 2*len(datas1) // 3 #2/3为训练集。
train_df = datas1[:train_size]
test_df = datas1[train_size:]
print('len train', len(train_df))
print('len test', len(test_df))
print(train_df.head(5))
print(test_df.head(5))
# 随机深林训练 导入包
from sklearn.ensemble import RandomForestClassifier
# 训练模型
clf = RandomForestClassifier(n_estimators=65, max_features="auto",max_depth=30,min_samples_split=200)
print(clf)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, precision_score, confusion_matrix, recall_score, accuracy_score
clf.fit(train_df.iloc[:,:-1],train_df.iloc[:,-1:].values.ravel())
# 模型调用
pre_train = clf.predict(train_df.iloc[:,:-1])
# print("在训练集预测的结果为:",pre_train)
print("在训练集的accuracy_score为:",accuracy_score(pre_train,train_df.iloc[:,-1:]))
pre_test = clf.predict(test_df.iloc[:,:-1])
# print("在测试集预测的结果为:",pre_test)
print("在测试集的accuracy_score为:",accuracy_score(pre_test,test_df.iloc[:,-1:]))
参考:https://www.joinquant.com/default/research/index?target=self&url=/default/research/redirect?next=/user/60085672476/clone_url?filename=/%E9%9A%8F%E6%9C%BA%E6%B7%B1%E6%9E%97%E9%A2%84%E6%B5%8B%E8%82%A1%E4%BB%B7.ipynb&url=https://file.joinquant.com/research/users/21781716153/share2/547b5c1052f981aee18d34cfc69e5eeb.htm
这个预测结果确实是很高,但是指标SOK和William R调用了未来数据,这个看了答案,不算数