

测试环境:
win7 ultimate(en)
Anaconda 3
一、安装Word2vec
Word2vec需要使用第三方gensim模块, gensim模块依赖numpy和scipy两个包,因此需要依次下载对应版本的numpy、scipy、gensim。
不过如果你使用Anaconda的话,前两个包已经安装好了,可能直接使用pip命令安装第三个包即可。
二、下载训练数据
下载地址如下:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
三、转换数据格式
解压后的数据是一个XML文件,而我们在Word2vec中使用的数据需要是txt格式的,所以必须进行转换,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#将xml的wiki数据转换为text格式
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])#得到文件名
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
if len(sys.argv) < 3:
print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open(outp, 'w')
wiki =WikiCorpus(inp, lemmatize=False, dictionary=[])#gensim里的维基百科处理类WikiCorpus
for text in wiki.get_texts():#通过get_texts将维基里的每篇文章转换位1行text文本,并且去掉了标点符号等内容
output.write(space.join(text) + "\n")
i = i+1
if (i % 10000 == 0):
logger.info("Saved "+str(i)+" articles.")
output.close()
logger.info("Finished Saved "+str(i)+" articles.")
没想到第一次运行失败,出现了“UnicodeEncodeError: 'gbk' codec can't encode character '\xf6' in position 892: i llegal multibyte sequence”的出错信息。
后来将output = open(outp, 'w')改成output = open(outp, 'w',,encoding='utf-8')终于正常了。
代码运行了一个多小时,运行完成了30万篇文章。
四、繁体转换
由于数据中包含有繁体文字,所以我们要用opencc将所有繁体字转换成简体字。
先下载opencc,再解压缩,然后将步骤三生成的文件复制到opencc文件夹,并在这个文件夹打开dos窗口(Shift+鼠标右键->在此处打开命令窗口),输入如下命令行:
opencc -i wiki.zh.txt -o wiki.zh.simp.txt -c t2s.json
几分钟后,会生成一个新的文件,即转成了简体中文的文件。
下载opencc,网址:https://bintray.com/package/files/byvoid/opencc/OpenCC
五、查看文件
我们的txt文件有1G多,用记事本之类的打开容易死机,可以用python自带的IO进行读取。
import codecs,sys f = codecs.open(‘wiki.zh.simp.txt‘,‘r‘,encoding="utf8") line = f.readline() print(line)
可以看到,原来的繁体已经转化成简体中文了。
六、分词
利用结巴分词进行分词处理,大约需要半个钟。
# -*- coding: utf-8 -*-
#逐行读取文件数据进行jieba分词
import jieba
import jieba.analyse
import jieba.posseg as pseg #引入词性标注接口
import codecs,sys
if __name__ == '__main__':
f = codecs.open('wiki.zh.simp.txt', 'r', encoding='utf8')
target = codecs.open('wiki.zh.simp.seg.txt', 'w', encoding='utf8')
print ('open files.')
lineNum = 1
line = f.readline()
while line:
print ('---processing ',lineNum,' article---')
seg_list = jieba.cut(line,cut_all=False)
line_seg = ' '.join(seg_list)
target.writelines(line_seg)
lineNum = lineNum + 1
line = f.readline()
print ('well done.')
f.close()
target.close()
7、Word2Vec模型训练
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#使用gensim word2vec训练脚本获取词向量
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')# 忽略警告
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
#print open('/Users/sy/Desktop/pyRoot/wiki_zh_vec/cmd.txt').readlines()
#sys.exit()
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s',level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# inp为输入语料, outp1 为输出模型, outp2为原始c版本word2vec的vector格式的模型
fdir = '/Users/sy/Desktop/pyRoot/wiki_zh_vec/'
inp = fdir + 'wiki.zh.simp.seg.txt'
outp1 = fdir + 'wiki.zh.text.model'
outp2 = fdir + 'wiki.zh.text.vector'
# 训练skip-gram模型
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count())
# 保存模型
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
代码运行完成后得到如下四个文件,其中wiki.zh.text.model是建好的模型,wiki.zh.text.vector是词向量。
五、模型测试
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#测试训练好的模型
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')# 忽略警告
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import gensim
if __name__ == '__main__':
fdir = '/Users/sy/Desktop/pyRoot/wiki_zh_vec/'
model = gensim.models.Word2Vec.load(fdir + 'wiki.zh.text.model')
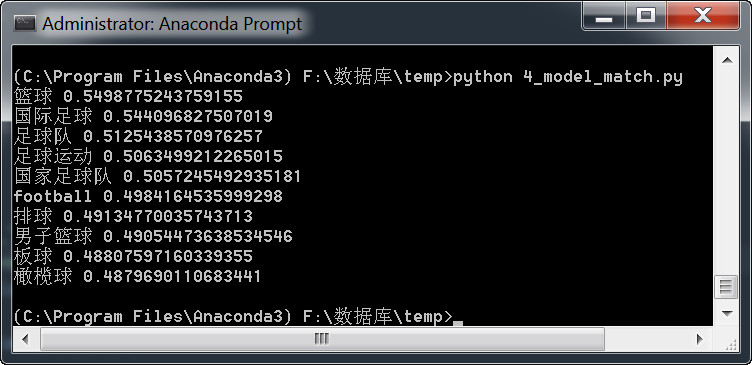
word = model.most_similar(u"足球")
for t in word:
print(t[0],t[1])
'''
word = model.most_similar(positive=[u'皇上',u'国王'],negative=[u'皇后'])
for t in word:
print t[0],t[1]
print model.doesnt_match(u'太后 妃子 贵人 贵妃 才人'.split())
print model.similarity(u'书籍',u'书本')
print model.similarity(u'逛街',u'书本')
'''
最终的结果:
除了word2vec,还可以用 Doc2Vec 得到文档/段落/句子的向量表达,大家可以尝试一下。
原载:蜗牛博客
网址:http://www.snailtoday.com
尊重版权,转载时务必以链接形式注明作者和原始出处及本声明。