

待处理文本:
郭富城方发声明否认炒作,真的是这样吗?我发布了头条文章:《罗生门:六小龄童上春晚究竟谁炒作?从这开8并怀念当年那美好的西游》
除夕还剩几天时间,这几天“猴哥”#六小龄童#突然成为网络热搜词,朋友圈全是“帮猴哥上春晚”的帖子。在充当“自来水”的同时,有人开始反思,“大圣”热闹上春晚话题是不是一种“情怀绑架”?有网友说“这年头,似乎打上情怀的标签,都能把一个看似毫无逻辑的事,套上隆重的仪式感,煽动起某种情绪。
呼吁六小龄童老师上春晚是好事,是人人盼望之事,但是不要被人牵着鼻子走,像央视张立,借着六小龄童老师炒作自己,中伤他人,这对章老师本人也不是益事,更不会促进什么期望实现。
发布了头条文章:《六小龄童,你真的不配上春晚!》 这两天大家都在为六小龄童鸣不平,咱说句公道话,六小龄童,你不配上春晚!别急着拍砖,听我细细道来!〔希望能静下来看完内容再评论〕[微笑]
凡事物极必反,现在给央视的舆论压力足够大了,甚至有点过了,而且我觉得现在最大的受害者还是六小龄童老师,不管最后上不上春晚,六小龄童老师现在估计都十分尴尬。大家可以稍微缓一缓,毕竟春晚的不可预测性是有太多先例的,04年那次六小龄童老师还是腊月28才接到通知临时进组的呢。[doge]
#热点#【六小龄童:如果上不了我就在家看春晚】“其实我完全没有料到,观众会对我上春晚的事这么轰动。我很感动,很感谢。除夕如果上(春晚),那就去给大家拜年,让大家高兴。如果没有上,我会和我的家人一起看春晚,继续支持央视春节联欢晚会。”昨日,@六小龄童 接受采访时说。
#支付宝集福#怎么了?全国人都在找敬业福,支付宝红包口令?还是希望看到#六小龄童上春晚#
如何看待有的人因为六小龄童老师没上春晚就骂tfboys
相关代码:
#coding=utf-8
import jieba
import jieba.analyse
import jieba.posseg as pseg
import re
class Extractkeys:
def removeEmoji(self, sentence):
return re.sub('\[.*?\]', '', sentence)
def CutWithPartOfSpeech(self, sentence):
sentence = self.removeEmoji(sentence)
words =jieba.cut(sentence)
wordlist=[]
for word in words:
wordlist.append(word)
return wordlist
def ExtractWord(self,wordlist):
sentence = ','.join(wordlist)
words = jieba.analyse.extract_tags(sentence,5)
wordlist = []
for w in words:
wordlist.append(w)
return wordlist
def RemoveStopWord(self,wordlist):
stopWords = self.GetStopWords()
keywords = []
for word in wordlist:
if word not in stopWords:
keywords.append(word)
return keywords
def extract(text):
ek = Extractkeys()
wordlist = ek.CutWithPartOfSpeech(text)
extractwords = ek.ExtractWord(wordlist)
return extractwords
# coding=utf-8
class PMI:
def __init__(self, document):
self.document = document
self.pmi = {}
self.miniprobability = float(1.0) / document.__len__()
self.minitogether = float(0)/ document.__len__()
self.set_word = self.getset_word()
def calcularprobability(self, document, wordlist):
"""
:param document:
:param wordlist:
:function : 计算单词的document frequency
:return: document frequency
"""
total = document.__len__()
number = 0
for doc in document:
if set(wordlist).issubset(doc):
number += 1
percent = float(number)/total
return percent
def togetherprobablity(self, document, wordlist1, wordlist2):
"""
:param document:
:param wordlist1:
:param wordlist2:
:function: 计算单词的共现概率
:return:共现概率
"""
joinwordlist = wordlist1 + wordlist2
percent = self.calcularprobability(document, joinwordlist)
return percent
def getset_word(self):
"""
:function: 得到document中的词语词典
:return: 词语词典
"""
list_word = []
for doc in self.document:
list_word = list_word + list(doc)
set_word = []
for w in list_word:
if set_word.count(w) == 0:
set_word.append(w)
return set_word
def get_dict_frq_word(self):
"""
:function: 对词典进行剪枝,剪去出现频率较少的单词
:return: 剪枝后的词典
"""
dict_frq_word = {}
for i in range(0, self.set_word.__len__(), 1):
list_word=[]
list_word.append(self.set_word[i])
probability = self.calcularprobability(self.document, list_word)
if probability > self.miniprobability:
dict_frq_word[self.set_word[i]] = probability
return dict_frq_word
def calculate_nmi(self, joinpercent, wordpercent1, wordpercent2):
"""
function: 计算词语共现的nmi值
:param joinpercent:
:param wordpercent1:
:param wordpercent2:
:return:nmi
"""
return (joinpercent)/(wordpercent1*wordpercent2)
def get_pmi(self):
"""
function:返回符合阈值的pmi列表
:return:pmi列表
"""
dict_pmi = {}
dict_frq_word = self.get_dict_frq_word()
print dict_frq_word
for word1 in dict_frq_word:
wordpercent1 = dict_frq_word[word1]
for word2 in dict_frq_word:
if word1 == word2:
continue
wordpercent2 = dict_frq_word[word2]
list_together=[]
list_together.append(word1)
list_together.append(word2)
together_probability = self.calcularprobability(self.document, list_together)
if together_probability > self.minitogether:
string = word1 + ',' + word2
dict_pmi[string] = self.calculate_nmi(together_probability, wordpercent1, wordpercent2)
return dict_pmi
最后一个:
#coding=utf-8
__author__ = 'root'
from PMI import *
import os
from extract import extract
if __name__ == '__main__':
documents = []
testfile = 'data.txt'
f = open(testfile, 'r')
data = f.readlines()
if data is not None:
for sentences in data:
extractwords = []
words = extract(sentences)
for word in words:
extractwords.append(word)
documents.append(set(extractwords))
pm = PMI(documents)
pmi = pm.get_pmi()
for p in pmi:
if pmi[p] > 1.5:
print p, pmi[p], '\n'
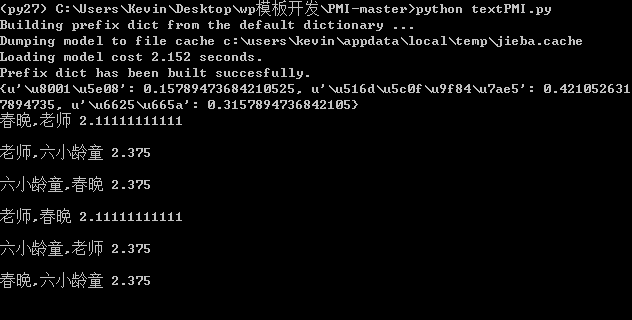
执行结果:
来源:https://blog.csdn.net/qq_30843221/article/details/50767590