

安装:
pip install nltk
安装后打算用了,没相到出现如下的错误:
Resource 'corpora/gutenberg' not found. Please use the NLTK Downloader to obtain the resource: >>> nltk.download()
然后再执行以下代码:
import nltk nltk.download()
会弹出一个界面,让你选择所需要安装的包,如果选择安装所有包的话,速度巨慢,所以还是要用哪个包就安装哪一个吧。
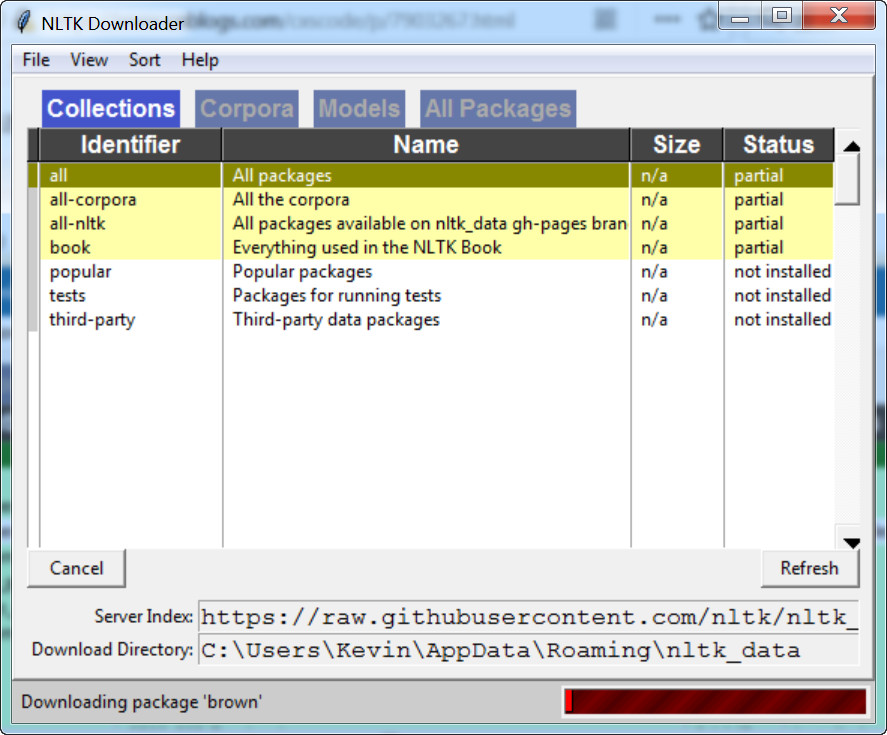
一、查看nltk有什么语料
from nltk.corpus import gutenberg
print (gutenberg.fileids())
from nltk import FreqDist
fd = FreqDist()
for word in gutenberg.words('austen-persuasion.txt'):
# fd.inc(word)
fd[word] += 1
print (fd.N())
print (fd.B())
刚开始执行的时候,出现:AttributeError: 'FreqDist' object has no attribute 'inc'
在网上找了一下,是nltk版本的原因,有人是这么说的:
The model was originally implemented with NLTK 2.x, ever since NLTK 3.0, they changed the interface of freqdist.
For quick fix, you may either downgrade NLTK to 2.x version, or go through the code and change all command of "freqdist.inc(sample, count)" to "freqdist[sample] += count".
我直接用freqdist[sample] 还是不行,原来是要使用
fd[word] += 1
但是又有答案说:
You should do it like so:
fd[word] += 1
But usually FreqDist is used like this:
fd = FreqDist(my_text)
Also look at the examples here:
http://www.nltk.org/book/ch01.html
下面是分别执行fd[word] += 1 与fd = FreqDist(word)的对比:
