

蜗牛博客VNPY学习记录:
VN.PY 2.0学习记录一(如何回测)
VN.PY 2.0学习记录二(策略开发)
Vn.py学习记录三(米筐教程)
VN.PY 2.0学习记录四(多线程、多进程)
Vn.py学习记录五–交易时间段及Widgets
Vn.py学习记录六(无界面模拟盘)
Vn.py学习记录七(V2.0.5版本)
Vnpy学习记录八(R-Breaker及pickle)
Vn.py学习记录九(事件驱动引擎)
VN.PY学习记录十(源码概述)
VNPY学习记录11(微信+Vscode)
VNPY学习记录12(父子进程、回调函数)
VNPY学习记录13(部署到云服务器,实现自动交易)
这是2019年VNPY量化交易实战教程附源码讲义 30课的学习记录。
一、导入jason文件为字典
jason文件
{
"rqUsername": "",
"rqPassword": "",
"symbols": ["I99", "IF99", "RB99", "TA99"]
}
而且可以通过其他文件来导入,见四的代码。
config = open('config.json')
setting = json.load(config)
备注:如果print(config)则显示“<_io.TextIOWrapper name='config.json' mode='r' encoding='cp936'>”
取值:
USERNAME = setting['rqUsername'] PASSWORD = setting['rqPassword']
二、MongoDB replace_one用法
使用replace_one()替代文档,如果未找到匹配的文档,就插入它
olddoc={...} #定义被替换的文档
newdoc={...} #定义要替换的文档
collection.replace_one(olddoc,newdoc,upsert=Ture)
for ix, row in df.iterrows():
bar = generateVtBar(row, symbol)
d = bar.__dict__
flt = {'datetime': bar.datetime}
cl.replace_one(flt, d, True)
关于df.iterrows(),请看这里
三、判断周末的方法(见四的代码)
四、父子进程
好处是子进程出错,不会影响父进程。
# encoding: UTF-8
import multiprocessing
from datetime import datetime, time
from time import sleep
from dataService import downloadDailyBarBySymbol, setting
#----------------------------------------------------------------------
def runChildProcess():
"""子进程运行函数"""
print "-" * 60
print u"开始更新日K线数据"
for symbol in setting["symbols"]:
downloadDailyBarBySymbol(symbol)
print u"日K线数据更新完成"
print "-" * 60
#----------------------------------------------------------------------
def runParentProcess():
"""守护进程运行函数"""
updateDate = None # 已更新数据的日期
while True:
# 每轮检查等待5秒,避免跑满CPU(浪费算力)
sleep(5)
currentTime = datetime.now().time()
print "#" * 60
print u"当前时间为:", currentTime
# 过滤交易日
today = datetime.now().date()
weekday = datetime.now().weekday()
if weekday in [5, 6]: # 从0开始,周六为5,周日为6
continue
# 每日5点后开始下载当日数据,通常3:15收盘后(国债)数据提供商需要一定时间清洗数据)
if currentTime <= time(17, 0):
continue
# 每日只需要更新一次数据
if updateDate == today:
continue
# 启动子进程来更新数据
p = multiprocessing.Process(target=runChildProcess)
p.start()
print u"启动子进程"
p.join()
print u"子进程已关闭"
# 记录当日数据已经更新
updateDate = today
if __name__ == "__main__":
runParentProcess()
五、回调函数
最典型的应用是爬虫,试想一下,你要采集一个网站,你是要将这个网站的所有url都全部获取到,再爬取这个url的数据,还是得到一条url,就爬取这个url的数据?如果是后者,那就要使用回调函数了。
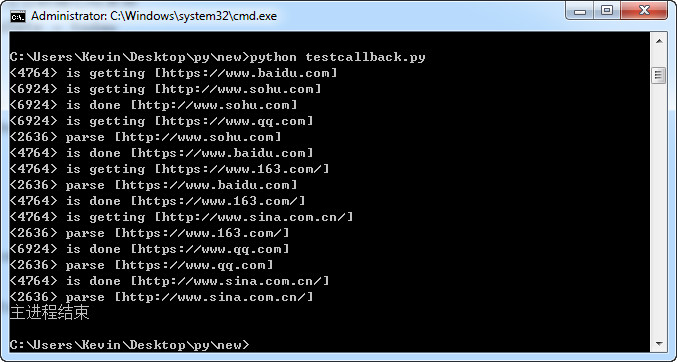
from multiprocessing import Pool
import os
import requests
def get_page(url):
print('<%s> is getting [%s]'%(os.getpid(),url))
res = requests.get(url).text
print('<%s> is done [%s]'%(os.getpid(),url))
return {'url': url, 'res': res}
def parse_page(res):
print('<%s> parse [%s]'%(os.getpid(),res['url']))
with open('ab.txt', 'a') as f:
f.write('%s - %s\n' % (res['url'], len(res['res'])))
f.write("==========================="+'\n')
if __name__ == '__main__':
urls = [
'https://www.baidu.com',
'http://www.sohu.com',
'https://www.qq.com',
'https://www.163.com/',
'http://www.sina.com.cn/',
]
p = Pool(2)
for url in urls:
#使用回调函数,当get_page下载完后,主线程调用parse_page自动处理get_page下载的结果,节省了parse_page的时间,该场景用于一个函数为耗时操作并且产生数据,另一个函数是非耗时操作,这样就节省了非耗时操作函数的时间
p.apply_async(get_page, args=(url,), callback=parse_page)
p.close()
p.join()
print('主进程结束')