

本文知识点:
1、复习了类的写法。
2、复习了scrapy先大范围取数,然后for循环取每一个item的用法。取大范围值的时候,在python中print不出来也没有问题,比如本文中的node_list,for循化中可以取出就可以了。
3、学习了写入Mysql时自动生成时间的方法。
4、学习了xpaht中的“.//”、“./”的写法。
5. Mysql避免数据重复插入的方法。
一、正则
折腾了一个早上,发现原来是目标网页的问题:http://rank.chinaz.com/?host=zz.xhj.com&st=0&c=&sortType=0&page=1
网页上的整体指数、PC指数、移动指数各栏数据在网页源码是有差异的,导致有的数据可以通过正则取到,有的取不到!
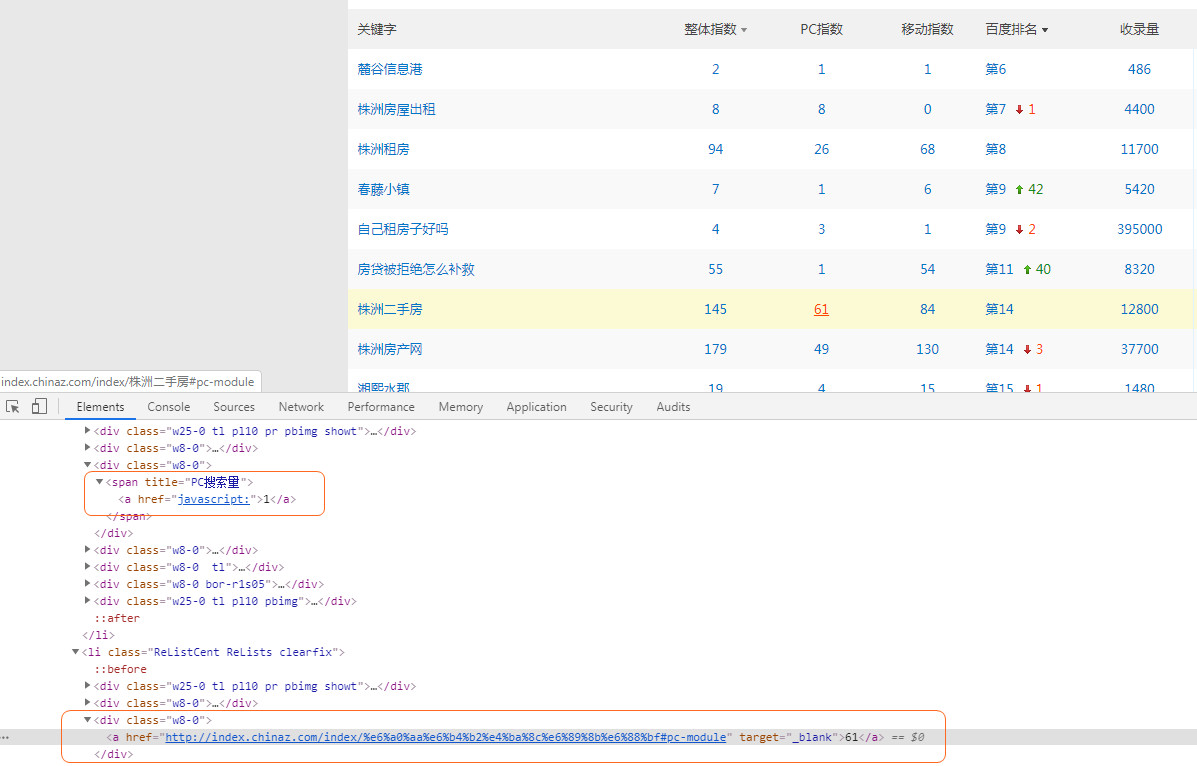
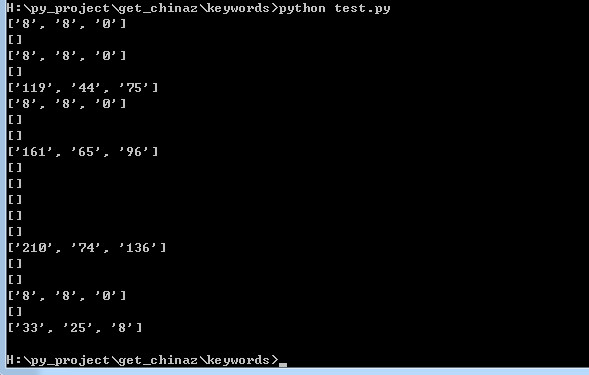
取的结果是这样的:
二、别人推荐的讲python类的视频
https://www.bilibili.com/video/av69455439?from=search&seid=406401960648305052
三、代码
后来放了几天,学习了一点正则,复习了一下scrapy,最后终于搞定了:
import requests
import re
import MySQLdb
from lxml import etree
import time
import datetime
#函数要调用必须先定义,而且顺序必须在前
class KeywordsTool():
"""一个采集chinaz关键词指数的类"""
def __init__(self, url):
# init进行初始化参数,把我们需要从外部传入的参数,作为类的属性
self.url = url
self.conn=MySQLdb.connect(host="localhost",user="root",passwd='',db="testpy" ,port=3306,charset="utf8") #连接数据库
self.cursor=self.conn.cursor() #定位一个指针
def get_url_content(self,url, max_try_number=5):
#封装的requests.get
try_num = 0
while True:
try:
return requests.get(url, timeout=5)
except Exception as http_err:
print(url, "抓取报错", http_err)
try_num += 1
if try_num >= max_try_number:
print("尝试失败次数过多,放弃尝试")
return None
def get_total_page(self,content):
#获取关键词总页数
selector = etree.HTML(content.text)
total_page_num = selector.xpath("//span[@class='col-gray02']/text()") # 获取总页数
total_page_num=re.sub(r'\D','',total_page_num[0])
return int(total_page_num)
def insert_to_db(self,word,total_index,pc_index,m_index):
#将数据插入Mysql数据库
dt=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
#insert ignore into 是避免重复插入
insert_result = self.cursor.execute("insert ignore into keywords(word,total_index,pc_index,m_index,create_time) VALUES ('%s',%s,%s,%s,str_to_date(\'%s\','%%Y-%%m-%%d %%H:%%i:%%s'))"%(word,total_index,pc_index,m_index,dt))
print("insert {}".format(insert_result))
print('[关键词:',word,'-----------已成功添加到数据库---------------')
# time.sleep(10)
self.conn.commit()
def get_keywords(self,i):
#获取网站上的关键词信息
url ="http://rank.chinaz.com/?host={}&st=0&c=&sortType=0&page={}".format(self.url,i)
content=requests.get(url).text
selector = etree.HTML(content)
node_list = selector.xpath("//li[@class='ReListCent ReLists clearfix']")
for node in node_list:
keywords = node.xpath("./div[@class='w25-0 tl pl10 pr pbimg showt']/a/text()")[0]
index_list = node.xpath("./div[@class='w8-0']/a/text()")
if len(index_list) ==0:
index_total = node.xpath(".//span[@title='整体搜索量']/a/text()")[0]
index_pc = node.xpath(".//span[@title='PC搜索量']/a/text()")[0]
index_m = node.xpath(".//span[@title='移动搜索量']/a/text()")[0]
else:
index_total = index_list[0]
index_pc = index_list[1]
index_m = index_list[2]
print('采集关键词:',keywords,',整体指数:',index_total,',PC指数:',index_pc,',移动指数:',index_m)
self.insert_to_db(keywords,index_total,index_pc,index_m)
print("已经完成第{}页数据的抓取".format(i))
print("*"*80)
time.sleep(2)
# ===抓取多页数据
def get_all_content(self):
url = "http://rank.chinaz.com/?host={}&st=0&c=&sortType=0&page=1".format(self.url)
r = self.get_url_content(url)
total_page_num = self.get_total_page(r) #这里调用函数self一定不能少
print("关键词总页数为{}页".format(total_page_num))
if total_page_num <= 9:
for i in range(1,total_page_num+1):
self.get_keywords(i)
else:
for i in range(1,10):
self.get_keywords(i)
A = KeywordsTool("sohu.com")
A.get_all_content()
四、关于Mysql版本的问题
想实现在mysql中插入数据的时候在create_time字段自动加入时间,可是搞了半天没搞出来,后来才发现原来是Mysql版本的问题,我的mysql版本太低了。找不到这个current_timestamp的选项。
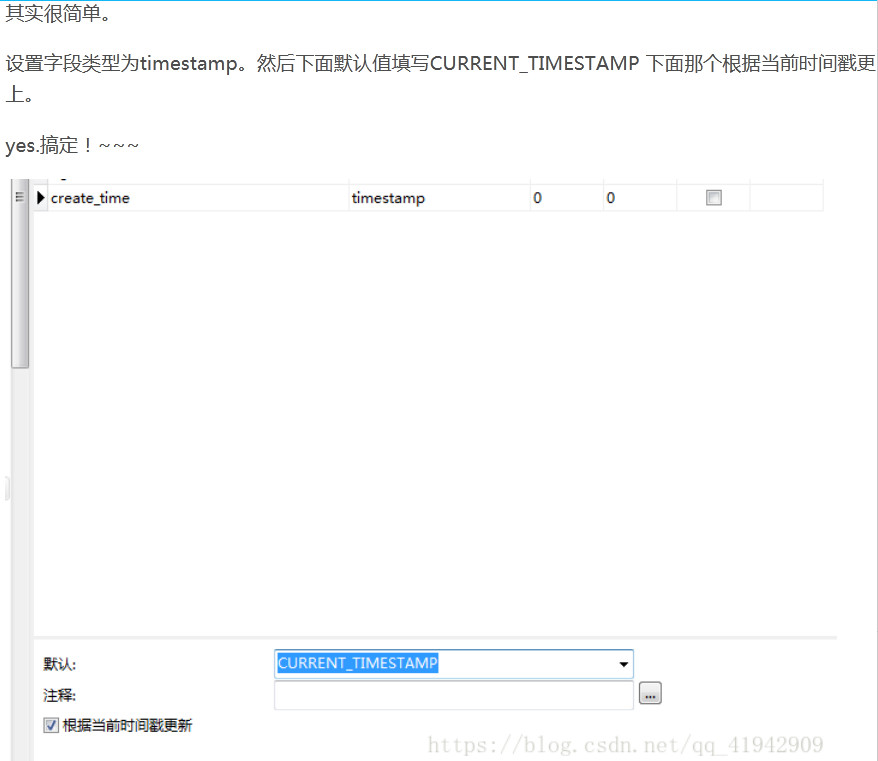
但是将时间插入mysql也老是出错,后来终于搞定了,应该用下面的代码
dt=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
sql = "INSERT INTO tb_emotion (name,datetime,emotion) VALUES ('%s',str_to_date(\'%s\','%%Y-%%m-%%d %%H:%%i:%%s'),'%s')" % (name,dt,emotion)
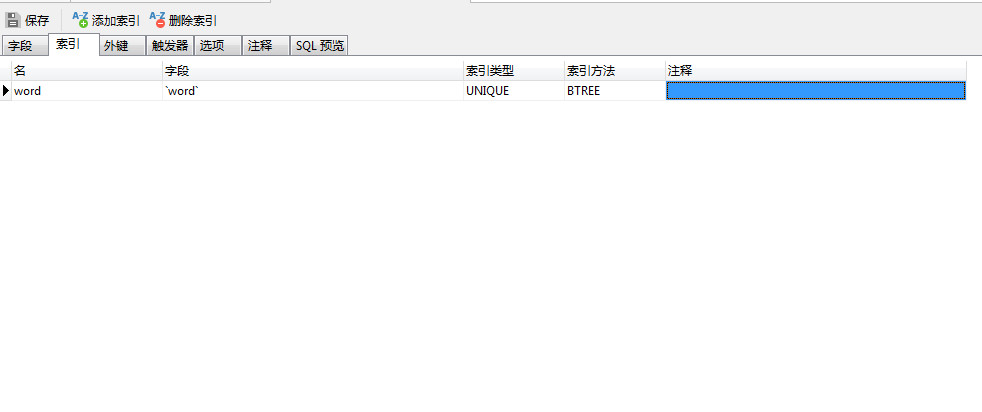
五、设置唯一索引
这个要在Navicat里面设置,在Mysql中没有找到设置的地方。
参考:https://www.jianshu.com/p/12b167812fdb
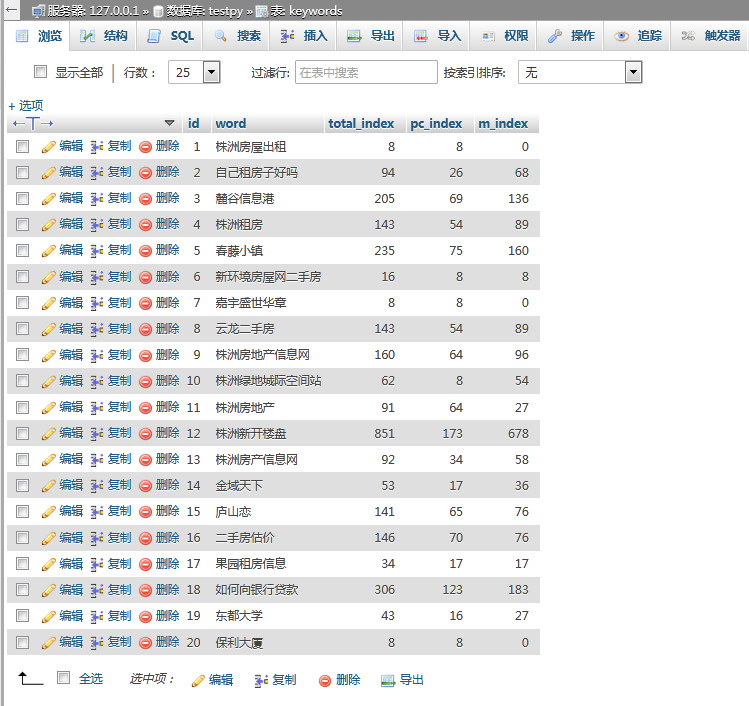
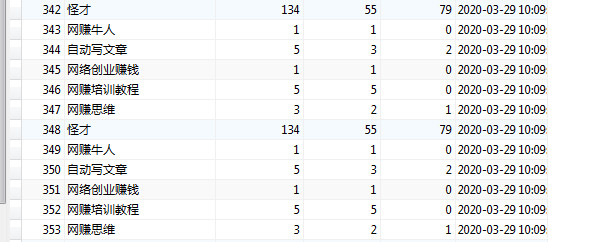
六、Mysql避免重复插入数据的方法
insert ignore into table_name(email,phone,user_id) values('test9@163.com','99999','9999'),
如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用。这样当有重复记录就会忽略,执行后返回数字0,如果插入成功,则返回数字1。如下图所示,后面的两次不执行。

参考:https://blog.csdn.net/qq_35044419/article/details/81974207
七、爬取相关关键词的
import requests
import re
from lxml import etree
import time
import datetime
#函数要调用必须先定义,而且顺序必须在前
class KeywordsTool():
"""一个采集chinaz关键词指数的类"""
def __init__(self, keyword):
# init进行初始化参数,把我们需要从外部传入的参数,作为类的属性
self.keyword = keyword
def get_url_content(self,url, max_try_number=5):
#封装的requests.get
try_num = 0
while True:
try:
return requests.get(url, timeout=5).text
except Exception as http_err:
print(url, "抓取报错", http_err)
try_num += 1
if try_num >= max_try_number:
print("尝试失败次数过多,放弃尝试")
return None
def get_total_page(self,content):
#获取关键词总页数
reg = r'共(\d+)页'
total_page_num = re.findall(reg,content)[0]
return int(total_page_num)
def insert_to_db(self,word):
filename = self.keyword+".txt"
with open(filename,'a') as f:
f.write(word+'\n')
def get_keywords(self,i):
#获取网站上的关键词信息
url = "https://data.chinaz.com/keyword/allindex/{}/{}".format(self.keyword,i)
content=requests.get(url).text
selector = etree.HTML(content)
node_list = selector.xpath("//li[@class='col-224 nofoldtxt']/a/text()")
for keyword in node_list:
self.insert_to_db(keyword)
print(keyword)
print("已经完成第{}页数据的抓取".format(i))
print("*"*80)
time.sleep(2)
# ===抓取多页数据
def get_all_content(self):
# url = "https://data.chinaz.com/keyword/analysis/{}".format(self.keyword)
url = "https://data.chinaz.com/keyword/allindex/{}/1".format(self.keyword)
r = self.get_url_content(url)
total_page_num = self.get_total_page(r) #这里调用函数self一定不能少
print("关键词总页数为{}页".format(total_page_num))
if total_page_num <= 5:
for i in range(1,total_page_num+1):
self.get_keywords(i)
else:
for i in range(1,6):
#最大只能抓取5页,第6页要登陆
self.get_keywords(i)
A = KeywordsTool("宠物")
A.get_all_content()
八、报错
今天将多个网站的数据插入mysql的时候,报以下的错误
MySQLdb._exceptions.ProgrammingError: (1064, "You have an error in your SQL synt
ax; check the manual that corresponds to your MariaDB server version for the rig
ht syntax to use near 's',16,16,0,str_to_date('2020-04-11 17:31:34','%Y-%m-%d %H
:%i:%s'))' at line 1")
原来这个关键词是“eva jaq's”,有一个逗号,导致插入数据库的时候出错。
通过将下面的句中的单引号改成双引号,双引号改成单引号解决。
self.cursor.execute("insert ignore into keywords(word,total_index,pc_index,m_index,create_time) VALUES ('%s',%s,%s,%s,str_to_date(\'%s\','%%Y-%%m-%%d %%H:%%i:%%s'))"%(word,total_index,pc_index,m_index,dt))