

一、简介
使用决策树, 线性回归, 向量机等机器学习的方法进行股票价格预测。
二、获取数据的方法
打开大智慧的股票界面,右键->复制数据,然后粘贴到Excel中即可。
然后在指标窗格切换指标,再复制到Excel中即可。
三、知识点
1.classification_report
其中列表左边的一列为分类的标签名(label),
precision recall f1-score三列分别为各个类别的精确度/召回率及 F1值.右边support列为每个标签的出现次数.
avg / total行为各列的均值(support列为总和)。
2.MinMaxScaler (归一化)
关于使用sklearn进行数据预处理,有归一化/标准化/正则化三种方法。
MinMaxScaler就是将属性缩放到一个指定的最大和最小值(通常是1-0)之间。
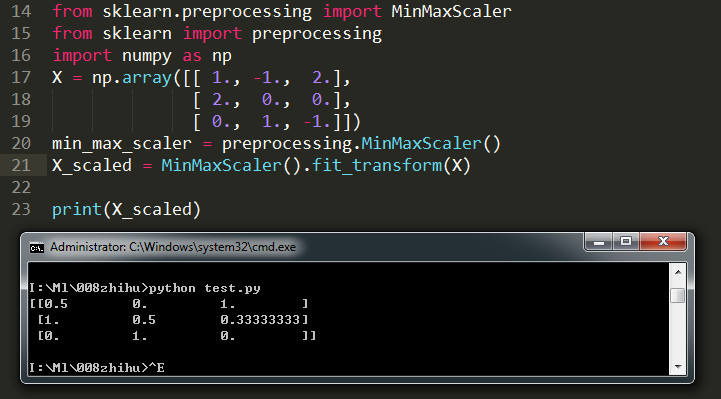
别人的测试结果
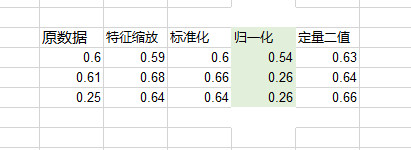
通过以上数据可以看出,除归一化处理的效果不好之外,其他三个方式都能有效提升模型性能。
3.zip 打包为元组的列表

四、结果

五、源代码
import pandas as pd
import time
# 加载数据集
data = pd.read_excel('data.xlsx')
# 拆分数据集
from sklearn.model_selection import train_test_split
y = data['label'].values #标签单独存给Y
X = data.drop(['label'],axis=1).values #其他数据都是X
# 拆分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
print('X_train的数据结构:{0}; \nX_test的数据结构:{1}; \ny_train的数据结构:{2}; \ny_test的数据结构:{3};'.format(
X_train.shape, X_test.shape, y_train.shape, y_test.shape))
# 生成决策树模型的结果
from sklearn.tree import DecisionTreeClassifier
clf2 = DecisionTreeClassifier()
t =time.time()
clf2.fit(X_train, y_train)
train_score = clf2.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
from sklearn.metrics import classification_report
# 模型结果验证及各性能指标
t0 =time.time()
pred = clf2.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('模型预测能力性能报告:')
print(clf2)
print(classification_report(y_test,pred ))
from sklearn.linear_model import LogisticRegression
# 生成线性回归模型的结果
t =time.time()
clf1 = LogisticRegression()
clf1.fit(X_train, y_train)
train_score = clf1.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf1.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('模型预测能力性能报告:')
print(clf1)
print(classification_report(y_test,pred ))
# 生成向量机模型的结果
from sklearn.svm import SVC
clf3 = SVC()
t =time.time()
clf3.fit(X_train, y_train)
train_score = clf1.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf3.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('模型预测能力性能报告:')
print(clf3)
print(classification_report(y_test,pred ))
# 特征缩放
from sklearn.preprocessing import MinMaxScaler
X_train = MinMaxScaler().fit_transform(X_train)
X_test = MinMaxScaler().fit_transform(X_test)
# 用for循环,批量带入基本模型中进行验证
model_name = ['决策树', '线性回归', '向量机']
for clf, name in zip([clf2, clf1, clf3], model_name):
clf.fit(X_train, y_train)
t =time.time()
train_score = clf1.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('模型预测能力性能报告:')
print(clf)
print(classification_report(y_test,pred ))
print("*"*100)
六、所有源代码
import pandas as pd
import numpy as np
import time
# 加载数据集
data = pd.read_excel('data.xlsx')
# 拆分数据集
from sklearn.model_selection import train_test_split
y = data['label'].values #标签单独存给Y,打印出来是个Ndarray(更高级的列表)
X = data.drop(['label'],axis=1).values #其他数据都是X
# 拆分数据,30%作为test数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
print('X_train的数据结构:{0}; \nX_test的数据结构:{1}; \ny_train的数据结构:{2}; \ny_test的数据结构:{3};'.format(
X_train.shape, X_test.shape, y_train.shape, y_test.shape))
# 生成决策树模型的结果
from sklearn.tree import DecisionTreeClassifier
clf2 = DecisionTreeClassifier()
t =time.time()
clf2.fit(X_train, y_train)
train_score = clf2.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
from sklearn.metrics import classification_report
# 模型结果验证及各性能指标
t0 =time.time()
pred = clf2.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('决策树模型预测能力性能报告:')
print(clf2)
print(classification_report(y_test,pred ))
# 生成线性回归模型的结果
from sklearn.linear_model import LogisticRegression
t =time.time()
clf1 = LogisticRegression()
clf1.fit(X_train, y_train)
train_score = clf1.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf1.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('线性回归模型预测能力性能报告:')
print(clf1)
print(classification_report(y_test,pred ))
# 生成向量机模型的结果
from sklearn.svm import SVC
clf3 = SVC()
t =time.time()
clf3.fit(X_train, y_train)
train_score = clf1.score(X_train, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf3.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('向量机模型预测能力性能报告:')
print(clf3)
print(classification_report(y_test,pred ))
#开始进行特征工程,特征工程的主要流程包括:数据预处理 -> 特征选择 两个主要内容。
# 特征缩放
from sklearn.preprocessing import MinMaxScaler
X_train = MinMaxScaler().fit_transform(X_train)
X_test = MinMaxScaler().fit_transform(X_test)
# 用for循环,批量带入基本模型中进行验证
model_name = ['决策树', '线性回归', '向量机']
for clf, name in zip([clf2, clf1, clf3], model_name):
clf.fit(X_train, y_train)
t =time.time()
train_score = clf1.score(X_train, y_train)
print('模型名称:{0},训练分数:{1}'.format(name,train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf.predict(X_test)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print(name+'模型预测能力性能报告:')
print(clf)
print(classification_report(y_test,pred ))
print("*"*100)
X_name = data.drop(['label'],axis=1).columns
print('所有的标签的名称是:{}'.format(X_name))
# 使用固定比例50%的自动选择
from sklearn.feature_selection import SelectPercentile
select1 = SelectPercentile(percentile=50)
select1.fit(X_train, y_train)
mask1 = select1.get_support()
print('使用固定比例50%的自动选择模型自动选出的特征分别是{0},一共有{1}个'.format(X_name[mask1], len(X_name[mask1])))
# 使用迭代特征进行选择——自动选择的高级模式
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE
select = RFE(RandomForestClassifier(n_estimators=100,random_state=42), n_features_to_select=21)
select.fit(X_train, y_train)
mask = select.get_support()
print('使用迭代特征模型自动选出的特征分别是{0},一共有{1}个'.format(X_name[mask], len(X_name[mask])))
# 挑选共有项的特征
new_mask = []
for ii in list(range(0,len(mask))):
if mask[ii] == True and mask1[ii]== True:
i = True
else:
i = False
new_mask.append(i)
print('模型自动选出的特征分别是{0},一共有{1}个'.format(X_name[new_mask], len(X_name[new_mask])))
# 按照自动选出来的特征组合出数据集
X_train_mask = select.transform(X_train)
X_test_mask = select.transform(X_test)
X_train_mask1 = select1.transform(X_train)
X_test_mask1 = select1.transform(X_test)
X_train_new_mask = X_train[:,new_mask]
X_test_new_mask = X_test[:,new_mask]
print('X_train_mask的维度是{}'.format(X_train_mask.shape))
print('X_test_mask的维度是{}'.format(X_test_mask.shape))
print('X_train_mask1的维度是{}'.format(X_train_mask1.shape))
print('X_test_mask1的维度是{}'.format(X_test_mask1.shape))
print('X_train_new_mask的维度是{}'.format(X_train_new_mask.shape))
print('X_test_new_mask的维度是{}'.format(X_test_new_mask.shape))
#评估数据集及模型
for clf, name in zip([clf2, clf1, clf3], model_name):
clf.fit(X_train_mask, y_train)
t =time.time()
train_score = clf.score(X_train_mask, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = clf.predict(X_test_mask)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print(name+'使用X_train_mask,模型预测能力性能报告:')
print(clf)
print(classification_report(y_test,pred ))
for clf, name in zip([clf2, clf1, clf3], model_name):
clf.fit(X_train_mask1, y_train)
t =time.time()
train_score = clf.score(X_train_mask1, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =t =time.time()
pred = clf.predict(X_test_mask1)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print(name+'使用X_train_mask1,模型预测能力性能报告:')
print(clf)
print(classification_report(y_test,pred ))
print("-"*50)
for clf, name in zip([clf2, clf1, clf3], model_name):
clf.fit(X_train_new_mask, y_train)
t =time.time()
train_score = clf.score(X_train_new_mask, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =t =time.time()
pred = clf.predict(X_test_new_mask)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print(name+'使用X_train_new_mask,模型预测能力性能报告:')
print(clf)
print(classification_report(y_test,pred ))
#优化性能最好的向量机
from sklearn.model_selection import GridSearchCV
param_grid = [{'kernel':['rbf'],
'C':[0.001, 0.01,0.1,1,10,100,1000],
'gamma':[0.001, 0.01,0.1,1,10,100,1000]},
{'kernel':['linear'],
'C':[0.001,0.01,0.1,1,10,100,1000]}]
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train_new_mask, y_train)
print('使用选出的macd,KDJ等指标,来尝试提高模型精度。最好的参数:{0}\n最好分数:{1}'.format(grid_search.best_params_, grid_search.best_score_))
# 直接上决策树算法,这个算法有很多扩展算法,直接选用这个
from sklearn.model_selection import GridSearchCV
entropy_thresholds = np.linspace(0, 1, 100)
gini_thresholds = np.linspace(0, 0.2, 100)
param_grid = [{'criterion': ['entropy'], 'min_impurity_decrease': entropy_thresholds},
{'criterion': ['gini'], 'min_impurity_decrease': gini_thresholds},
{'max_depth': np.arange(2,10)},
{'min_samples_split': np.arange(2,30,2)}]
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train_new_mask, y_train)
print('使用决策树算法,最好的参数:{0}\n最好分数:{1}'.format(grid_search.best_params_, grid_search.best_score_))
#使用随机森林模型
rfc = RandomForestClassifier(n_estimators=1000, criterion='gini') # 生成1000个决策树进行交叉
t =time.time()
rfc.fit(X_train_new_mask, y_train)
train_score = rfc.score(X_train_new_mask, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = rfc.predict(X_test_new_mask)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('使用随机森林模型模型预测能力性能报告:')
print(rfc)
print(classification_report(y_test,pred ))
# 使用vote算法对模型再次进行优化
from mlxtend.classifier import EnsembleVoteClassifier
clf1 = LogisticRegression()
clf2 = RandomForestClassifier(n_estimators=1000, criterion='gini')
clf3 = SVC(kernel='rbf',C=0.1,gamma=1,probability=True)
clf4 = DecisionTreeClassifier()
eclf1 = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3, clf4],voting='hard', verbose=1)
t =time.time()
eclf1.fit(X_train_new_mask, y_train)
train_score = eclf1.score(X_train_new_mask, y_train)
print('训练分数:{0}'.format(train_score))
print('训练共用时间:{0}秒'.format(time.time()-t))
t0 =time.time()
pred = eclf1.predict(X_test_new_mask)
print('预测结束,用时:{0}秒'.format(time.time()-t0))
print('使用vote算法对模型再次进行优化后,模型预测能力性能报告:')
print(eclf1)
print(classification_report(y_test,pred ))
# 将每个标的的预测概率进行输出——只输出前20个
np.set_printoptions(suppress=True)
print(eclf1.predict_proba(X_test_new_mask[:20]))
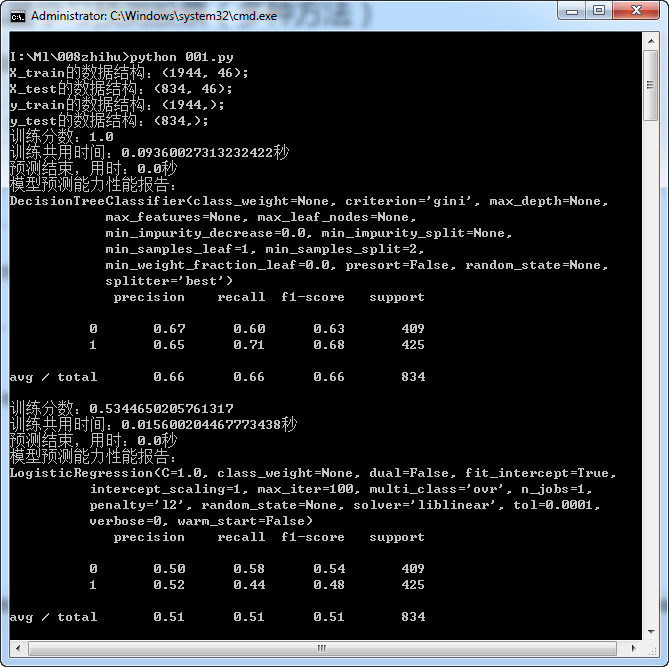
运行的结果:
I:\Ml\008zhihu>python 001.py
X_train的数据结构:(1944, 46);
X_test的数据结构:(834, 46);
y_train的数据结构:(1944,);
y_test的数据结构:(834,);
训练分数:1.0
训练共用时间:0.09360027313232422秒
预测结束,用时:0.0秒
决策树模型预测能力性能报告:
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
precision recall f1-score support
0 0.66 0.67 0.66 419
1 0.66 0.64 0.65 415
accuracy 0.66 834
macro avg 0.66 0.66 0.66 834
weighted avg 0.66 0.66 0.66 834
训练分数:0.5339506172839507
训练共用时间:0.015600204467773438秒
预测结束,用时:0.0秒
线性回归模型预测能力性能报告:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.51 0.51 0.51 419
1 0.51 0.51 0.51 415
accuracy 0.51 834
macro avg 0.51 0.51 0.51 834
weighted avg 0.51 0.51 0.51 834
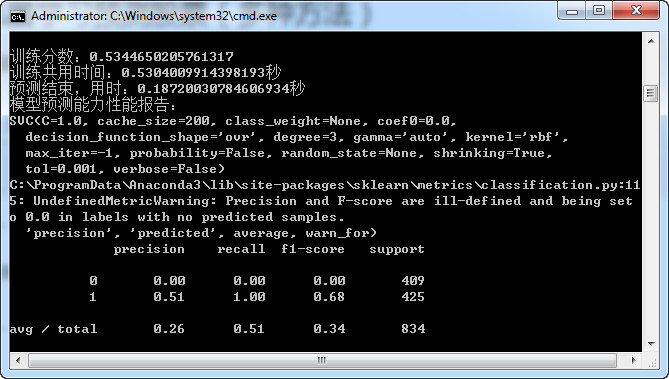
训练分数:0.5339506172839507
训练共用时间:0.32760071754455566秒
预测结束,用时:0.09360003471374512秒
向量机模型预测能力性能报告:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
0 0.51 0.58 0.54 419
1 0.51 0.44 0.47 415
accuracy 0.51 834
macro avg 0.51 0.51 0.50 834
weighted avg 0.51 0.51 0.50 834
模型名称:决策树,训练分数:0.4876543209876543
训练共用时间:0.0秒
预测结束,用时:0.0秒
决策树模型预测能力性能报告:
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
precision recall f1-score support
0 0.59 0.36 0.45 419
1 0.53 0.74 0.62 415
accuracy 0.55 834
macro avg 0.56 0.55 0.53 834
weighted avg 0.56 0.55 0.53 834
********************************************************************************
********************
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:939
: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html.
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regressio
n
extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG)
模型名称:线性回归,训练分数:0.7680041152263375
训练共用时间:0.0秒
预测结束,用时:0.0秒
线性回归模型预测能力性能报告:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.80 0.70 0.75 419
1 0.73 0.83 0.78 415
accuracy 0.76 834
macro avg 0.77 0.77 0.76 834
weighted avg 0.77 0.76 0.76 834
********************************************************************************
********************
模型名称:向量机,训练分数:0.7680041152263375
训练共用时间:0.0秒
预测结束,用时:0.07800030708312988秒
向量机模型预测能力性能报告:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
0 0.77 0.68 0.72 419
1 0.71 0.80 0.75 415
accuracy 0.74 834
macro avg 0.74 0.74 0.74 834
weighted avg 0.74 0.74 0.74 834
********************************************************************************
********************
所有的标签的名称是:Index(['成交额', '成交笔数', 'MA1', 'MA2', 'MA3', 'MA4', 'MA
5', 'MA6', 'MID', 'UPPER',
'LOWER', 'AR', 'BR', 'BIAS1', 'BIAS2', 'BIAS3', 'unknow1', 'CJBS', 'CR',
'MA1.1', 'MA2.1', 'MA3.1', 'PDI', 'MDI', 'ADX', 'ADXR', 'K', 'D', 'K.1',
'D.1', 'J', 'DIFF', 'DEA', 'MACD', 'unknow2', 'unknow3', 'RSI1', 'RSI2',
'RSI3', 'WR1', 'WR2', 'JCS', 'JCM', 'JCL', 'DDD', 'AMA'],
dtype='object')
使用固定比例50%的自动选择模型自动选出的特征分别是Index(['成交额', 'AR', 'BR', 'B
IAS1', 'BIAS2', 'BIAS3', 'unknow1', 'CR', 'PDI',
'MDI', 'K', 'D', 'K.1', 'D.1', 'J', 'DIFF', 'MACD', 'unknow3', 'RSI1',
'RSI2', 'RSI3', 'WR1', 'WR2'],
dtype='object'),一共有23个
使用迭代特征模型自动选出的特征分别是Index(['AR', 'BIAS1', 'BIAS2', 'BIAS3', 'unk
now1', 'CJBS', 'CR', 'PDI', 'MDI',
'ADX', 'K', 'D', 'K.1', 'D.1', 'J', 'MACD', 'RSI1', 'RSI2', 'WR1',
'WR2', 'JCL'],
dtype='object'),一共有21个
模型自动选出的特征分别是Index(['AR', 'BIAS1', 'BIAS2', 'BIAS3', 'unknow1', 'CR',
'PDI', 'MDI', 'K',
'D', 'K.1', 'D.1', 'J', 'MACD', 'RSI1', 'RSI2', 'WR1', 'WR2'],
dtype='object'),一共有18个
X_train_mask的维度是(1944, 21)
X_test_mask的维度是(834, 21)
X_train_mask1的维度是(1944, 23)
X_test_mask1的维度是(834, 23)
X_train_new_mask的维度是(1944, 18)
X_test_new_mask的维度是(834, 18)
训练分数:1.0
训练共用时间:0.015599966049194336秒
预测结束,用时:0.0秒
决策树使用X_train_mask,模型预测能力性能报告:
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
precision recall f1-score support
0 0.61 0.47 0.53 419
1 0.57 0.70 0.63 415
accuracy 0.58 834
macro avg 0.59 0.58 0.58 834
weighted avg 0.59 0.58 0.58 834
训练分数:0.7602880658436214
训练共用时间:0.0秒
预测结束,用时:0.0秒
线性回归使用X_train_mask,模型预测能力性能报告:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.80 0.70 0.75 419
1 0.73 0.83 0.78 415
accuracy 0.76 834
macro avg 0.77 0.76 0.76 834
weighted avg 0.77 0.76 0.76 834
训练分数:0.7834362139917695
训练共用时间:0.5616011619567871秒
预测结束,用时:0.23400020599365234秒
向量机使用X_train_mask,模型预测能力性能报告:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
0 0.80 0.70 0.75 419
1 0.73 0.82 0.77 415
accuracy 0.76 834
macro avg 0.77 0.76 0.76 834
weighted avg 0.77 0.76 0.76 834
训练分数:1.0
训练共用时间:0.0秒
预测结束,用时:0.0秒
决策树使用X_train_mask1,模型预测能力性能报告:
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
precision recall f1-score support
0 0.59 0.50 0.54 419
1 0.56 0.64 0.60 415
accuracy 0.57 834
macro avg 0.57 0.57 0.57 834
weighted avg 0.57 0.57 0.57 834
--------------------------------------------------
训练分数:0.7659465020576132
训练共用时间:0.0秒
预测结束,用时:0.0秒
线性回归使用X_train_mask1,模型预测能力性能报告:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.80 0.72 0.76 419
1 0.74 0.82 0.78 415
accuracy 0.77 834
macro avg 0.77 0.77 0.77 834
weighted avg 0.77 0.77 0.77 834
--------------------------------------------------
训练分数:0.7870370370370371
训练共用时间:0.4836008548736572秒
预测结束,用时:0.23400044441223145秒
向量机使用X_train_mask1,模型预测能力性能报告:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
0 0.80 0.72 0.76 419
1 0.75 0.82 0.78 415
accuracy 0.77 834
macro avg 0.77 0.77 0.77 834
weighted avg 0.77 0.77 0.77 834
--------------------------------------------------
训练分数:1.0
训练共用时间:0.015599966049194336秒
预测结束,用时:0.0秒
决策树使用X_train_new_mask,模型预测能力性能报告:
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
precision recall f1-score support
0 0.59 0.49 0.54 419
1 0.56 0.66 0.61 415
accuracy 0.57 834
macro avg 0.58 0.57 0.57 834
weighted avg 0.58 0.57 0.57 834
训练分数:0.7587448559670782
训练共用时间:0.0秒
预测结束,用时:0.0秒
线性回归使用X_train_new_mask,模型预测能力性能报告:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.80 0.70 0.75 419
1 0.73 0.83 0.78 415
accuracy 0.76 834
macro avg 0.77 0.76 0.76 834
weighted avg 0.77 0.76 0.76 834
训练分数:0.7818930041152263
训练共用时间:0.10920047760009766秒
预测结束,用时:0.04680013656616211秒
向量机使用X_train_new_mask,模型预测能力性能报告:
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
0 0.79 0.74 0.77 419
1 0.75 0.81 0.78 415
accuracy 0.77 834
macro avg 0.77 0.77 0.77 834
weighted avg 0.77 0.77 0.77 834
使用选出的macd,KDJ等指标,来尝试提高模型精度。最好的参数:{'C': 100, 'gamma': 1,
'kernel': 'rbf'}
最好分数:0.7844724776720643
使用决策树算法,最好的参数:{'criterion': 'gini', 'min_impurity_decrease': 0.0020
2020202020202}
最好分数:0.693422203376355
训练分数:1.0
训练共用时间:13.275623083114624秒
预测结束,用时:0.28080058097839355秒
使用随机森林模型模型预测能力性能报告:
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=1000,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
precision recall f1-score support
0 0.87 0.26 0.41 419
1 0.56 0.96 0.71 415
accuracy 0.61 834
macro avg 0.72 0.61 0.56 834
weighted avg 0.72 0.61 0.56 834
Fitting 4 classifiers...
Fitting clf1: logisticregression (1/4)
Fitting clf2: randomforestclassifier (2/4)
Fitting clf3: svc (3/4)
Fitting clf4: decisiontreeclassifier (4/4)
训练分数:0.8955761316872428
训练共用时间:21.24723744392395秒
预测结束,用时:0.3120005130767822秒
使用vote算法对模型再次进行优化后,模型预测能力性能报告:
EnsembleVoteClassifier(clfs=[LogisticRegression(C=1.0, class_weight=None,
dual=False, fit_intercept=True,
intercept_scaling=1,
l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None,
penalty='l2', random_state=None,
solver='lbfgs', tol=0.0001,
verbose=0, warm_start=False),
RandomForestClassifier(bootstrap=True,
ccp_alpha=0.0,
class_weight=None,
criterion='gini...
shrinking=True, tol=0.001, verbose=False),
DecisionTreeClassifier(ccp_alpha=0.0,
class_weight=None,
criterion='gini',
max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0
,
presort='deprecated',
random_state=None,
splitter='best')],
refit=True, verbose=1, voting='hard', weights=None)
precision recall f1-score support
0 0.79 0.73 0.76 419
1 0.75 0.80 0.77 415
accuracy 0.77 834
macro avg 0.77 0.77 0.77 834
weighted avg 0.77 0.77 0.77 834
[[0.29904357 0.70095643]
[0.38052022 0.61947978]
[0.04736433 0.95263567]
[0.70955564 0.29044436]
[0.79065533 0.20934467]
[0.11818586 0.88181414]
[0.12765114 0.87234886]
[0.29053959 0.70946041]
[0.11113169 0.88886831]
[0.7328489 0.2671511 ]
[0.58150786 0.41849214]
[0.38384207 0.61615793]
[0.35686211 0.64313789]
[0.25780496 0.74219504]
[0.28229374 0.71770626]
[0.56169932 0.43830068]
[0.37888313 0.62111687]
[0.40678589 0.59321411]
[0.18140309 0.81859691]
[0.34179083 0.65820917]]
参考:https://zhuanlan.zhihu.com/p/54853160