

应用场景:
有时我们从网上采集了大量的关键词,因为是采集的,难免其中含有一些敏感关键词,如果是做中文站的话,最好将这些关键词去掉。在网上找到了一个Python脚本,不过是python 2.x的,我修改了一下,改成了python 3.X的,在改的过程中遭遇如下错误:
python TypeError: a bytes-like object is required, not 'str'
TypeError: 'in
' requires string as left operand, not bytes
其实主要是因为python2和python3的编码问题,只要将原代码中的“encode('utf-8')”这些去掉就可以了。
最终运行结果如下(过滤了原来文件中的“funny”、“guy”这两个单词):
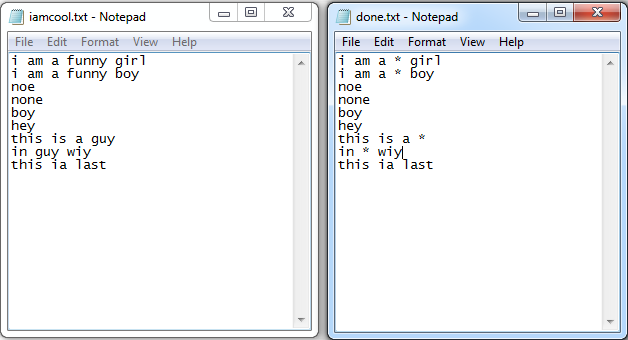
代码如下:
import sys
op_txt = open('done.txt', 'a')
class NaiveFilter():
'''Filter Messages from keywords
very simple filter implementation
>>> f = NaiveFilter()
>>> f.add("sexy")
>>> f.filter("hello sexy baby")
hello **** baby
'''
def __init__(self):
self.keywords = set([])
def parse(self, path):
for keyword in open(path):
self.keywords.add(keyword.strip().lower())
# print self.keywords
def filter(self, message, replss="*"):
# print(message)
message = message.lower()
# print(message)
for k in self.keywords:
if k in message:
message = message.replace(k, replss)
else:
pass
op_txt.write('%s\n' % message)
print(message)
# return message
if __name__ == '__main__':
f = NaiveFilter()
f.parse("illegal.txt") # 这里面放要敏感词或不想要的词等
a = [i.strip() for i in open('keywords.txt').readlines()] # keywords.txt是将要过滤的词库
c = len(a)
for i in range(c):
f.filter(a[i])
原文在这里:http://bigwayseo.com