

一、数据库结构
先发表一篇文章:
ask_questions表:

ask_tags表:
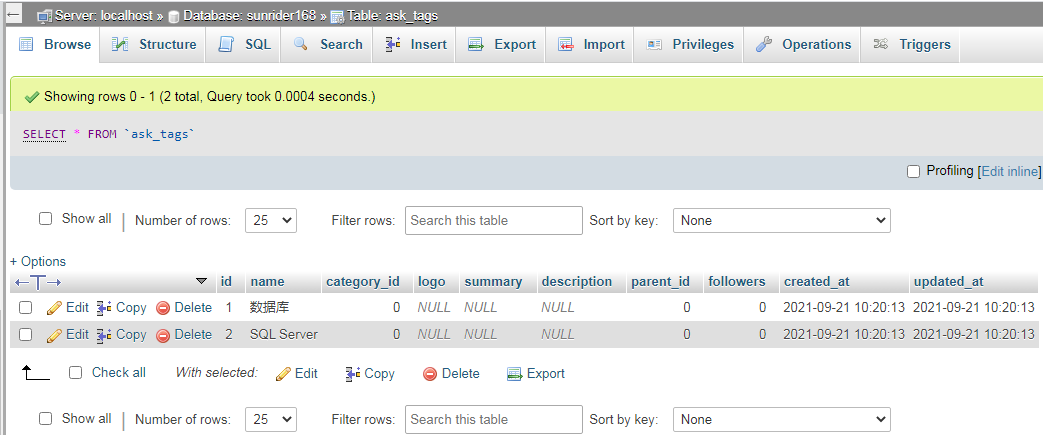
这个表也有数据,它是问题和标签的关系表,taggable_id是对应的文章ID。
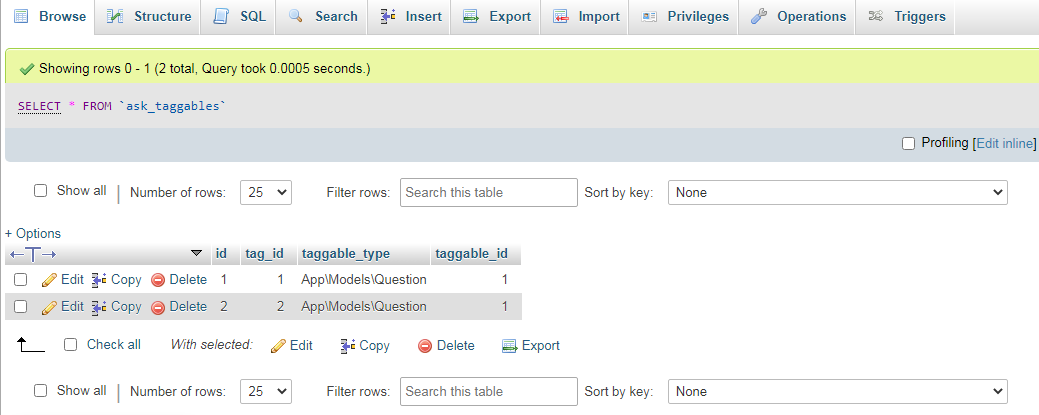
二、代码
# coding:utf-8
import MySQLdb as mdb
import datetime,time,re,sys,random
reload(sys)
sys.setdefaultencoding('utf-8')
con = mdb.connect('127.0.0.1','root','{pasword}','wenda_gogochuan',charset = 'utf8mb4',unix_socket='/tmp/mysql.sock')
con2 = mdb.connect('127.0.0.1','root','{pasword}','wenda_gogochuan',charset = 'utf8mb4',unix_socket='/tmp/mysql.sock')
def sql_w(sql):
cur = con.cursor()
try:
cur.execute(sql)
con.commit()
except:
con.rollback()
print "Error!!!"
print sql
sys.exit()
def sql_r_num(sql):
cur = con.cursor()
cur.execute(sql)
data = cur.fetchone()
return data[0]
user_nums = sql_r_num("select max(id) from ask_users")
def random_date_q():
a1=(2018,12,1,0,0,0,0,0,0) #设置开始日期时间元组(1976-01-01 00:00:00)
a2=(2019,4,1,0,0,0,0,0,0) #设置结束日期时间元组(1990-12-31 23:59:59)
start=time.mktime(a1) #生成开始时间戳
end=time.mktime(a2) #生成结束时间戳
#随机生成日期字符串
t=random.randint(start,end) #在开始和结束时间戳中随机取出一个
date_touple=time.localtime(t) #将时间戳生成时间元组
date=time.strftime("%Y-%m-%d %H:%M:%S",date_touple) #将时间元组转成格式化字符串(1976-05-21)
return date
def random_date_a():
a1=(2019,3,1,0,0,0,0,0,0) #设置开始日期时间元组(1976-01-01 00:00:00)
a2=(2019,4,14,0,0,0,0,0,0) #设置结束日期时间元组(1990-12-31 23:59:59)
start=time.mktime(a1) #生成开始时间戳
end=time.mktime(a2) #生成结束时间戳
#随机生成日期字符串
t=random.randint(start,end) #在开始和结束时间戳中随机取出一个
date_touple=time.localtime(t) #将时间戳生成时间元组
date=time.strftime("%Y-%m-%d %H:%M:%S",date_touple) #将时间元组转成格式化字符串(1976-05-21)
return date
max_qid = sql_r_num("select max(id) from ask_questions")
if max_qid == None: #ask_questions没有数据,首次导入
max_qid = 1
with con:
cur = con.cursor()
cur.execute("select * from caiji")
nums = int(cur.rowcount)
for i in range(nums):
row = cur.fetchone()
q_title = row[0]
q_update = row[1]
q_desc = row[2] #提问描述
a_list = row[3].split('|||') #回答内容;每个人的回答以“|||”为分隔,如:不错啊|||很好|||谢谢楼主帮忙
a_update = row[4].split('|||')
a_num = len(a_list)
updatetime = random_date_q()
print(">>> qid: %s" % (max_qid + i))
print(q_title)
sql_ask_questions = '''INSERT INTO ask_questions (user_id,category_id,title,description,price,hide,answers,views,followers,collections,comments,device,status,created_at,updated_at) VALUES (%s,%s,"%s","%s",%s,%s,%s,%s,%s,%s,%s,%s,%s,"%s","%s")''' % (
random.randint(3,user_nums), #user_id
0,#category_id
q_title.replace('"','\''),#title
q_desc.replace('"','\''),#description
0,#price
0,#hide
a_num,#answers
random.randint(50,300),#views
random.randint(0,30),#followers
0,#collections
0,#comments
1,#device
1,#status
updatetime,#created_at
updatetime,#updated_at
)
sql_w(sql_ask_questions) #写入问题
for content in a_list:
a_date = random_date_a()
sql_ask_answers = '''INSERT INTO ask_answers (question_title,question_id,user_id,content,supports,oppositions,comments,device,status,adopted_at,created_at,updated_at) VALUES ("%s",%s,%s,"%s",%s,%s,%s,%s,%s,%s,"%s","%s")''' % (
q_title.replace('"','\''), #question_title
max_qid + i, #question_id
random.randint(3,user_nums), #user_id
content.replace('"','\''), #content
0,#supports
0,#oppositions
0,#comments
1,#device
1,#status
"Null",#adopted_at
a_date, #created_at
a_date, #updated_at
)
sql_w(sql_ask_answers) #写入回答内容
https://wenda.tipask.com/article/14076
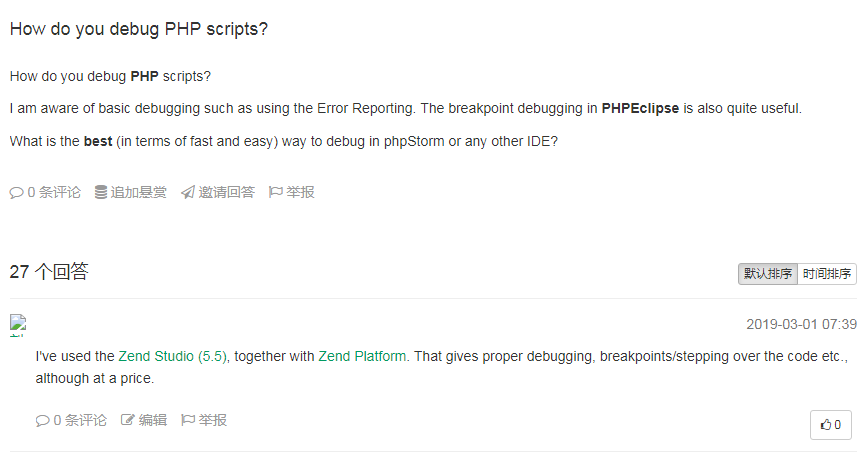
三、效果
tipask效果:
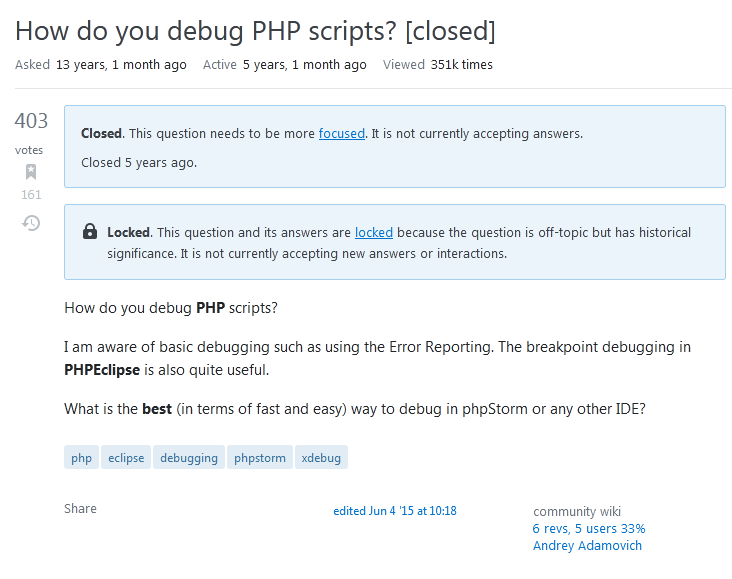
原网页效果:
四、报错
后来出现了一个奇怪的问题,用代码写入数据库没有报错,可是tipask前端不显示。
后来找了很久才找出原因,原业是tipask有一个字段adopted_at, 它的字段类型是时间,可是我用程序批量插入的时候,插入了一个时间进去,就导致了这个问题。
后来写入数据库的时候,直接将这个字段给忽略掉,因为它有一个默认字段"Null",这样答案也就可以正常显示了。