

如果你的电脑中装有多个浏览器,如果你使用python requests爬取数据,如果遇到下面这样的报错,考虑可能是浏览器的原因引起。
https://www.xxx.com.html 抓取报错 HTTPSConnectionPool(host='www.xxx.com', port=443): Max retries exceeded with url: /20100_.html (Caused by ProxyError('Cannot connect to proxy.', NewConnectionError('
: Failed to establish a new connection: [WinError 10061] No connection could be made because the target machine actively refused it')))
一、爬虫对应的是chrome浏览器
在我的电脑上,爬虫对应的是chrome浏览器。因为chrome浏览器设置了全局代理,所以导致爬虫报代理错误的信息。
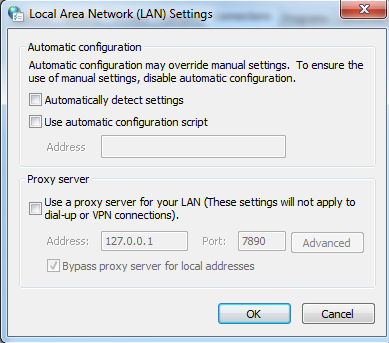
取消浏览器的代理,爬虫工作正常。
二、google翻译错误的问题
我的google翻译代码,之前是正常工作的,不过进行了上面的浏览器设置之后,无法进行翻译了,后来设置chrome为代理模式,又正常了。