

一、进度
第1章 已经完成
第2章 已经完成 May-20-2020
第3章 已经完成
第4章 已经完成
第5章 已经完成
第6章 python入门 全部学完
第7章 全部学完
第8章 全部学完
第9章 已经完成。
第10章 已经完成。
第11章 已经完成。
从5月8日购买课程,到5月21日全部学完,几乎花了半个月的时间,不过学到的东西还是挺多的。
二、小知识
1.
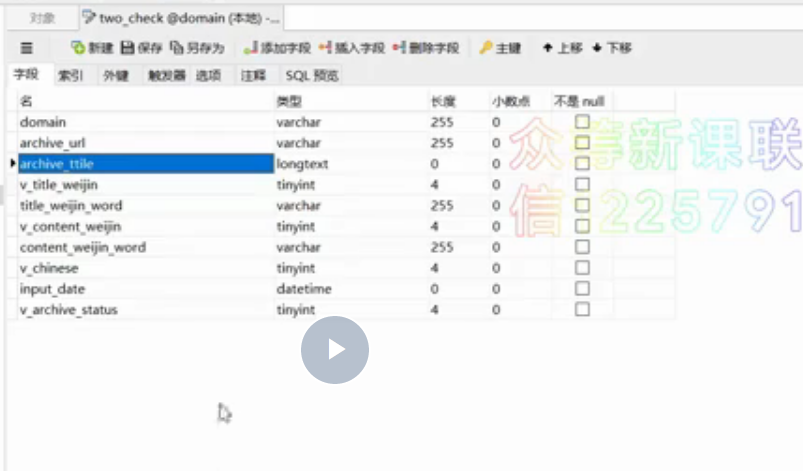
2.使用了whoosh来创建索引
https://www.jb51.net/article/175965.htm
3.使用七牛云存图片
https://www.jianshu.com/p/9fea18d668b8
4.仿网站
原来可以通过浏览器打开,检查元素,再删除不需要的代码。
5.音频转文字。
喜马拉雅FM专辑下载工具
录音啦 转文字
6.判断蜘蛛
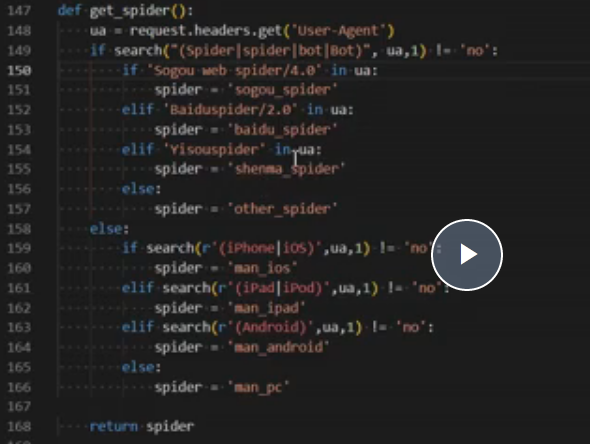
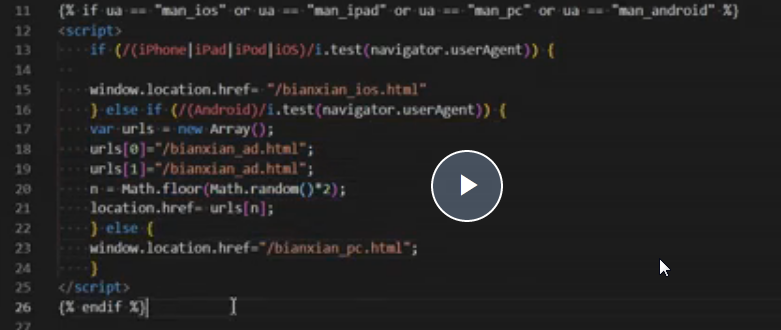
7.一些代码
img = "<img src = '{}'> alt='{}'".format(image,keyword)
bd_xgss = open("bd_xgss").readlines()
10
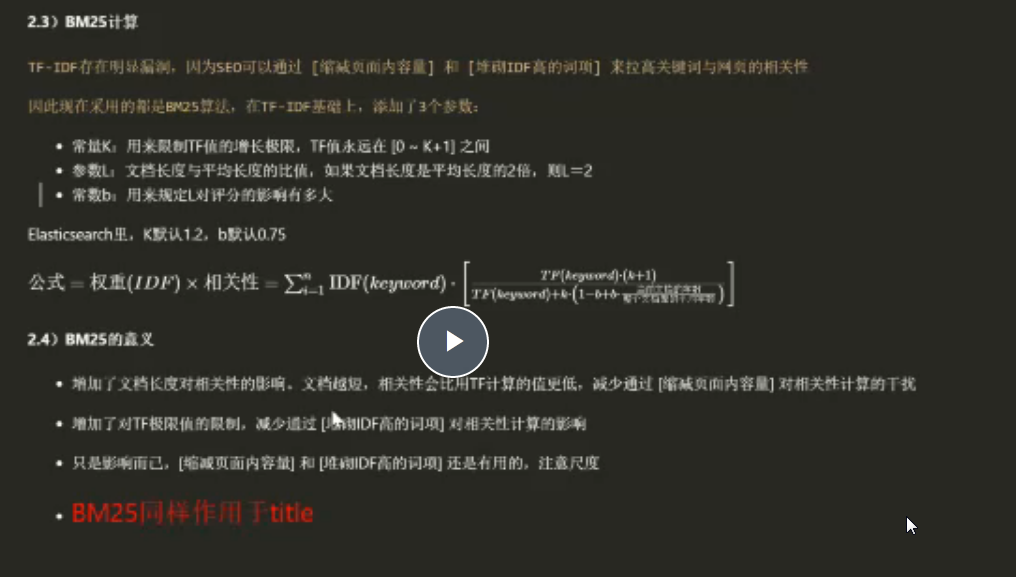
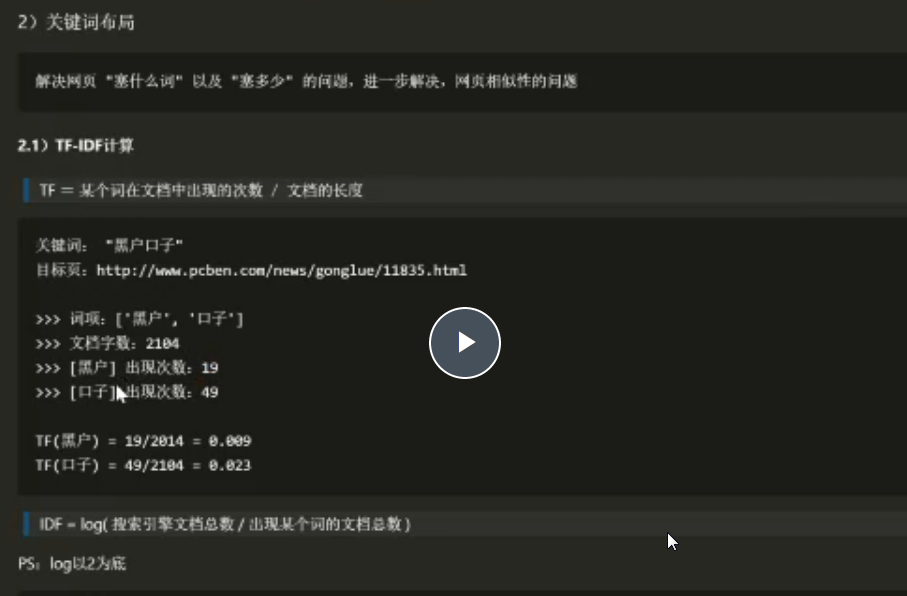
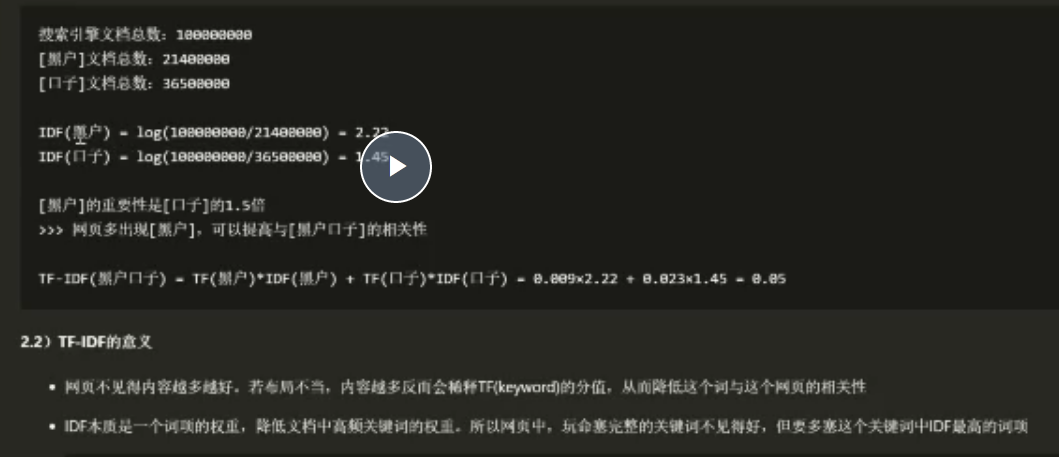
去除html
https://www.jb51.net/article/78833.htm
三、一些有用的网站
http://www.baijingapp.com/exchange/
https://www.bfseo.com/
http://www.ping.pe/
http://www.91vps.com/bohao.asp 拨号vps
http://www.innojoy.com/search/home.html 专利搜索 PA = '%百度%' and TI='点击'
十一、代理IP
芝麻代理:http://www.zhimaruanjian.com/ (138 P k4)
按次提取(http://h.zhimaruanjian.com/getapi/)
好一点的:https://www.abuyun.com/ (d8Pk4)(只能按天,按月交费,对我不合适)
https://scrapinghub.com/crawlera
https://www.2808proxy.com/ 获取代理,比芝麻代理好。但是现在无法注册 只支持企业用户。
github:
https://github.com/a631381602
笨方法学python:
https://www.bilibili.com/video/BV1aE411V7xc?from=search&seid=10644831406964451443
Python3爬虫从入门到精通 - 崔庆才
https://www.bilibili.com/video/BV1a7411f76Z?from=search&seid=14608294082970297983
十二、flask站群
nginx配置
server
{
listen 80;
server_name www.lignton.com m.lignton.com;
index index.php index.html index.htm default.php default.htm default.html;
root /www/wwwroot/www.lignton.com;
#SSL-START SSL相关配置,请勿删除或修改下一行带注释的404规则
#error_page 404/404.html;
#SSL-END
#ERROR-PAGE-START 错误页配置,可以注释、删除或修改
#error_page 404 /404.html;
#error_page 502 /502.html;
#ERROR-PAGE-END
#PHP-INFO-START PHP引用配置,可以注释或修改
include enable-php-70.conf;
#PHP-INFO-END
#REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效
include /www/server/panel/vhost/rewrite/www.lignton.com.conf;
#REWRITE-END
#禁止访问的文件或目录
location ~ ^/(\.user.ini|\.htaccess|\.git|\.svn|\.project|LICENSE|README.md)
{
return 404;
}
# 获取域名
if ($host ~* ([a-z0-9][a-z0-9\-]+?\.(?:com|cn|net|org|info|la|xyz|cc|co|gz|ah|gd|nm|sh|tj|gov|sx|gz|sh|sc|faith|date|space)(?:\.cn)?)$ ) {
set $domain $1;
}
# 补全www
if ($host ~* ^([a-z0-9][a-z0-9\-]+?\.(?:com|cn|net|org|info|la|cc|xyz|co|gz|ah|gd|nm|sh|tj|gov|sx|gz|sh|sc|faith|date|space)(?:\.cn)?)$){
rewrite ^/(.*)$ http://www.$domain/$1 permanent;
}
set $baidu_trans 0;
if ( $http_user_agent ~* (transcoder) ) {
set $baidu_trans "${baidu_trans}1";
}
set $mobile 0;
if ( $http_user_agent ~* (nokia|sony|ericsson|mot|samsung|htc|sgh|lg|sharp|sie-|philips|panasonic|alcatel|lenovo|iphone|ipod|blackberry|meizu|android|netfront|symbian|ucweb|windowsce|palm|operamini|mobi|openwave|nexusone|cldc|midp|wap) ) {
set $mobile "${mobile}1";
}
# 移动客户端访问跳转至M站
if ($host !~* ^m\.([a-z0-9][a-z0-9\-]+?\.(?:com|cn|net|org|xyz|info|la|cc|co|gz|ah|gd|nm)(?:\.cn)?)$){
set $baidu_trans "${baidu_trans}2";
set $mobile "${mobile}2";
}
if ($baidu_trans = "012"){
rewrite ^/(.*)$ http://m.$domain/$1 permanent;
}
if ($mobile = "012"){
rewrite ^/(.*)$ http://m.$domain/$1;
}
# 禁止Scrapy等工具的抓取,注意已经取消curl抓取
if ($http_user_agent ~* (Scrapy|HttpClient)) {
return 403;
}
# 禁止恶意user_agent访问
if ($http_user_agent ~* (MegaIndex|MJ12bot|NHN|Twiceler|AhrefsBot|YandexBot)) {
return 403;
}
# 禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
#一键申请SSL证书验证目录相关设置
location ~ \.well-known{
allow all;
}
# 图片及javascrpt缓存
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 30d;
error_log off;
access_log /dev/null;
}
location ~ .*\.(js|css)?$
{
expires 12h;
error_log off;
access_log /dev/null;
}
access_log /www/wwwlogs/www.lignton.com.log;
error_log /www/wwwlogs/www.lignton.com.error.log;
# proxy_pass与flask主程序端口保持一致
location / {
proxy_pass http://127.0.0.1:5000/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
三、中国Seo的一些牛人:
https://seofangfa.com/seo-mingren/seo-hero.html
可以留个联系方式吗?想购买课程,谢谢