

产生流量的来源关键词60%~70%都是有规律可循。所以我强烈的认为,挖掘关键词的本质是为了找到这种规律,然后快速的制造大量的、较优质的页面。
对于没规律的词咋办?搜索量高就留着人工编辑做专题,如:“住房公积金如何提取”;至于没搜索量的,直接删掉。
有规律的关键词基本就3种:“{词前缀}..+词根+..{词后缀}” 、“{词前缀}..+词根” 、“词根+..{词后缀}” ,如何快速准确的从挖掘的关键词中找到这种规律?
以‘招聘’为词根,用百度商情通过牛B的无限循环大法挖出23万关键词,然后打开一看………完全不知道该干什么…….

提取前后词缀,发现是这个样子滴:
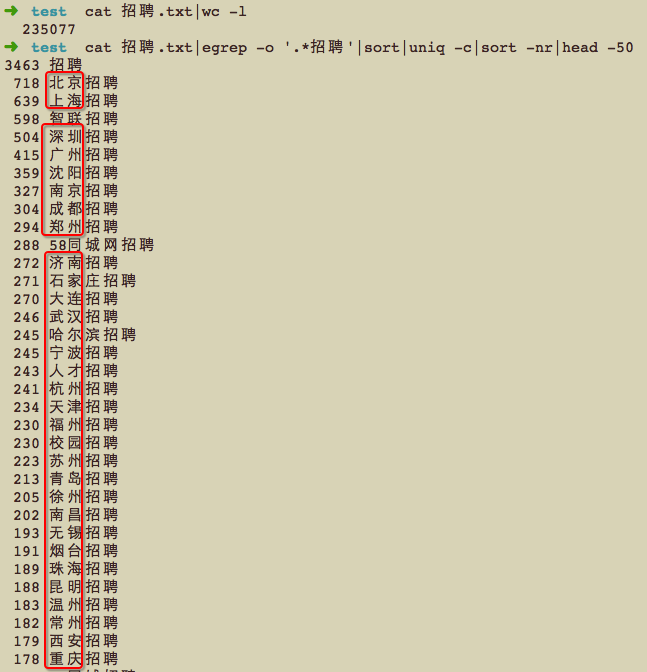
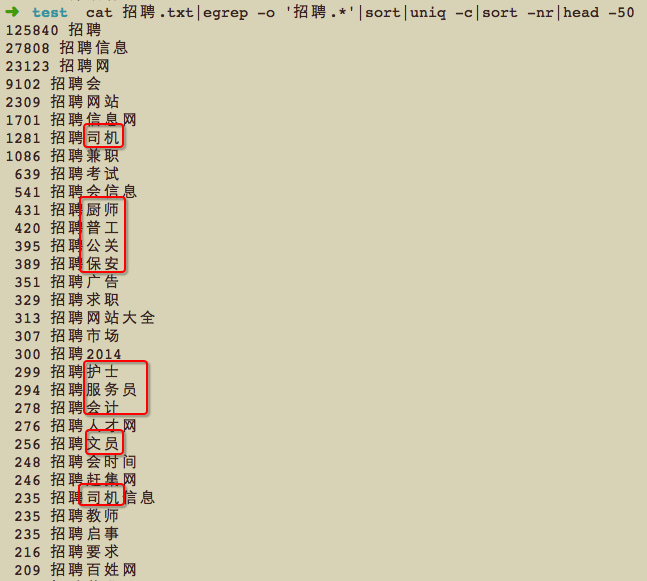
全是‘城市’变量,对找关键词规律造成很大的干扰,对于‘北京招聘、沈阳招聘、天津招聘’完全可以用统一的‘{city}招聘’替代,同理还有一堆‘招聘销售、招聘客服’等,职位变量可以用‘招聘{job}’替代。
怎么替换呢?从搜狗细胞词库下载几份地域词,导入jieb字典dict.txt(导入前别忘了先去重啊亲),再从站内数据库中提取一列职位词,按照jieba标准添加权值和词性后再次导入dict.txt
因为职位词需要完整匹配,不能再被切开,所以权值要设的很高,比如500。词性随便设,我设的是‘zwc’
然后用python将词性为城市(ns)和职位(zwc)分别替换成‘{city}’和‘{job}’,再看一下替换后的关键词,是这个样子滴:
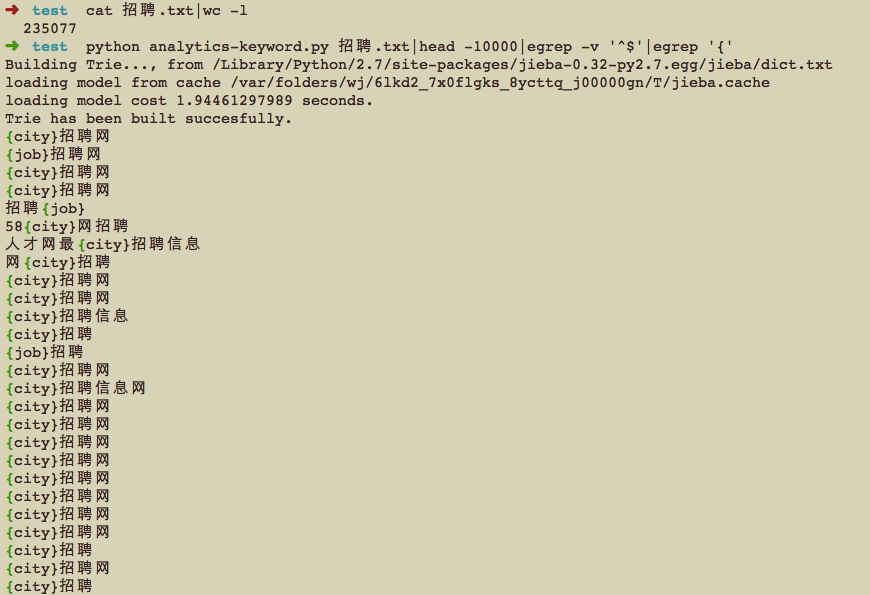
看下数据,原来有23万的关键词,替换掉城市和职位后去重只剩下8万,也就是说23万里面有15万是一样的词….其中替换城市19万,职位4万

这次再把词缀过滤出来看下,比之前清晰多了~~~~
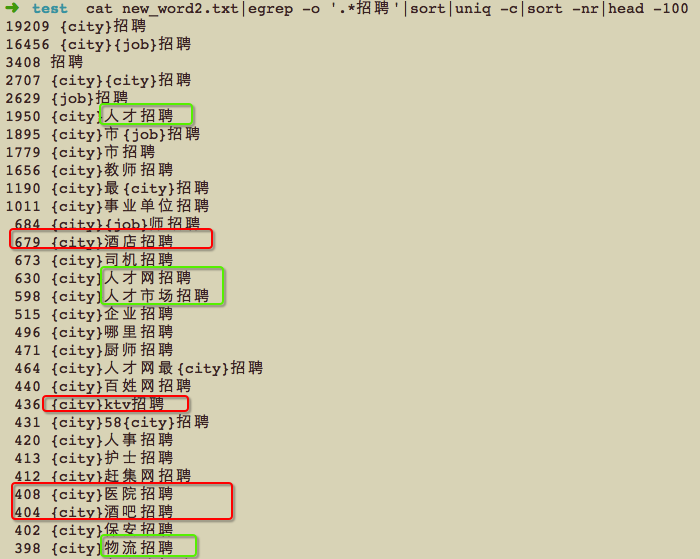
为毛这里的司机、厨师、护士没有替换成‘{job}’呢…因为导入dict.txt之前自己手贱,把字数为2的职位词都删掉了…….除了几个显而易见的规律外,发现‘{city}酒店招聘’,酒店属于‘工作场所’变量,于是乎再找一堆工作场所的词,如:医院招聘、工厂招聘、校园招聘、电子厂招聘、农村信用社招聘、影楼招聘、4S店招聘….,又能扩展一批,剩下以此类推
之后把所有的规律都汇总:
{city招聘 126219
{job}招聘信息 27890
{job}招聘网 23208
{city}招聘会 9121
{city | job}人才招聘网 3003
{city}{工作场所}招聘 2824
{city}兼职招聘 2660
{city | job}人才招聘 2587
{city}招聘网站 2326
企业招聘 1548
人才网招聘 526
人才市场招聘 554
招聘信息网 1705
应届生招聘 248
………..
招聘的规律比较少,看下工资相关的:
平均工资 2295
工资标准 1632
工资待遇 1084
工资多少 999
绩效工资 901
最低工资 899
工资水平 592
基本工资 415
工资高吗 412
工资查询 397
工资计算 369
退休工资 164
员工工资 200
人均工资 178
加班工资 188
后缀:
725 工资表
311 工资怎么样
284 工资吗
275 工资单
264 工资改革
250 工资是多少
247 工资怎么算
239 工资条
219 工资制度
216 工资文件
175 工资证明
169 工资调整
165 工资最高
146 工资计算器
…….
根据这些词缀加上变量就组成了一堆规律,看哪些含义相近的词汇可以放在一个title中, 最后结合网站内容的实际情况,按逻辑关系画个类似夜息大大的关键词结构图,一个词库挖掘到提取有效关键词的环节就做完了
来源:GoGo闯