

一、TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。

注:TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
通谷理解:
Term Frequency
假设我们有一组英文文本文档,希望对与查询“the brown cow更相关的文档进行排名。 一种简单的开始方法是删除不包含所有三个单词“ the”,“ brown”和“ cow”的文档,但这仍然留下许多文档。 为了进一步区分它们,我们可以计算每个术语在每个文档中出现的次数; 术语在文档中出现的次数称为术语频率。但是,在文档长度相差很大的情况下,通常会进行调整。
Inverse document frequency
因为术语“ the”是如此常见,所以术语频率会倾向于错误地强调恰好更频繁地使用“ the”一词的文档,而没有给予足够有意义的术语“ brown”和“ cow”。 与较少见的单词“棕色”和“牛”不同,术语“ the”不是区分相关和不相关文档和术语的好关键字。 因此,引入了反向文档频率因子,其减少了在文档集中非常频繁出现的术语的权重,并增加了很少出现的术语的权重。
二、算法实现
1.word_count
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import TfidfVectorizer docs=["Until the early 1930s, Turkey followed a neutral foreign policy with the West by developing joint friendship and neutrality agreements. ", "These bilateral agreements aligned with Atatürk's worldview. By the end of 1925, Turkey had signed fifteen joint agreements with Western states.", "In the early 1930s, changes and developments in world politics required Turkey to make multilateral agreements to improve its security. Atatürk strongly believed that close cooperation between the Balkan states based on the principle of equality would have an important effect on European politics.", "These states had been ruled by the Ottoman Empire for centuries and had proved to be a powerful force. While the origins of the Balkan agreement may date as far back as 1925, the Balkan Pact came into being in the mid-1930s.", "Several important developments in Europe helped the original idea materialize, such as improvements in the Turkish-Greek alliance and the rapprochement between Bulgaria and Yugoslavia. The most important factor in driving Turkish foreign policy from the mid-1930s onwards was the fear of Italy."] doc = CountVectorizer() word_count=doc.fit_transform(docs) word_count.shape print(word_count)
执行结果是:
(0, 95) 1
(0, 90) 2
(0, 30) 1
(0, 1) 1
(0, 93) 1
(0, 41) 1
(0, 66) 1
(0, 44) 1
(0, 75) 1
(0, 100) 1
(0, 97) 1
(0, 20) 1
(0, 27) 1
(0, 59) 1
(0, 45) 1
(0, 7) 1
(0, 67) 1
(0, 3) 1
(1, 90) 1
(1, 93) 1
(1, 100) 2
(1, 20) 1
(1, 59) 1
(1, 3) 2
(1, 91) 1
: :
2.idf_weights
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True) tfidf_transformer.fit(word_count) df_idf = pd.DataFrame(tfidf_transformer.idf_, index=doc.get_feature_names(),columns=["idf_weights"]) df_idf.sort_values(by=['idf_weights']).head(40)

3.tfidf
tf_idf_vector=tfidf_transformer.transform(word_count) feature_names = doc.get_feature_names() first_document_vector=tf_idf_vector[1] df = pd.DataFrame(first_document_vector.T.todense(), index=feature_names, columns=["tfidf"]) df.sort_values(by=["tfidf"],ascending=False).head(45)
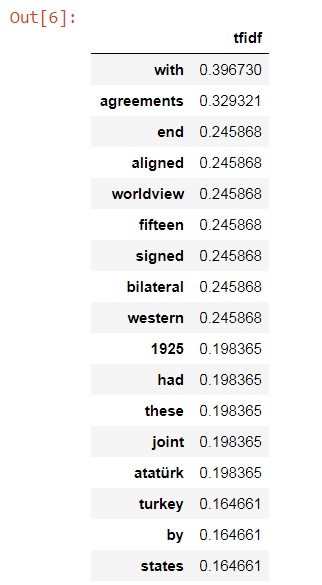
4.tfidf
tfidf_vectorizer=TfidfVectorizer(use_idf=True) tfidf_vectorizer_vectors=tfidf_vectorizer.fit_transform(docs) first_vector_tfidfvectorizer=tfidf_vectorizer_vectors[1] df = pd.DataFrame(first_vector_tfidfvectorizer.T.todense(), index=tfidf_vectorizer.get_feature_names(), columns=["tfidf"]) df.sort_values(by=["tfidf"],ascending=False).head(45)
