

一、高速公路公司名单
http://summary.jrj.com.cn/hybk/400128959.shtml
http://data.eastmoney.com/bkzj/421.html
二、下载数据
网址:http://www.sse.com.cn/disclosure/listedinfo/regular/
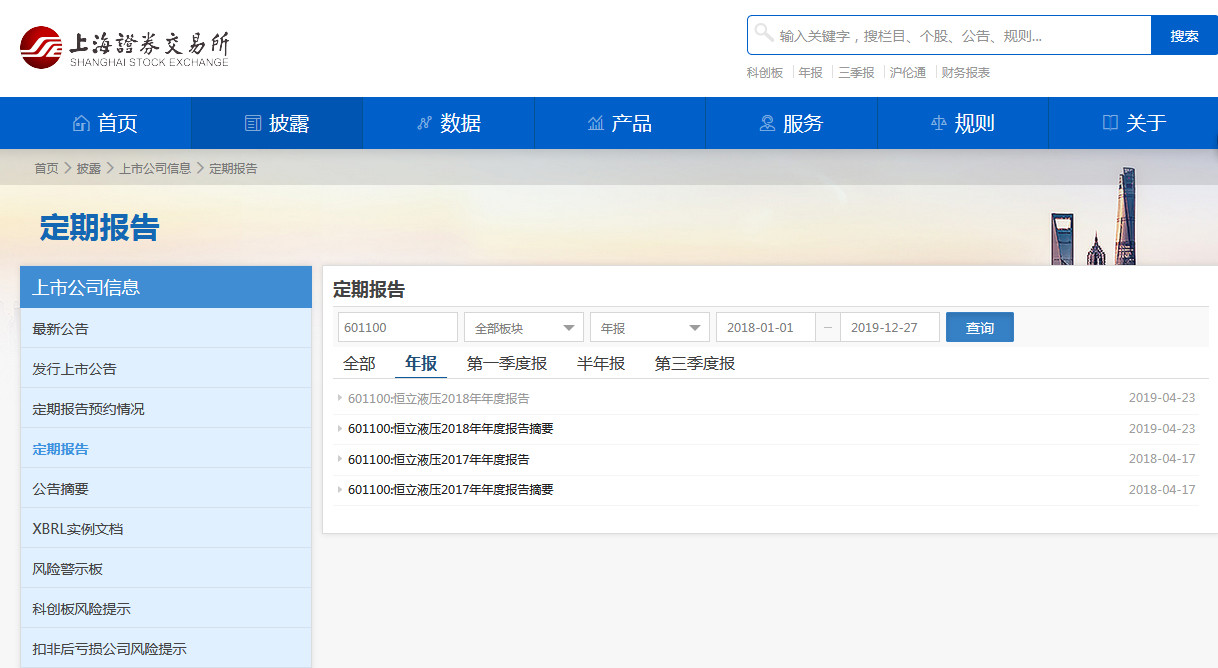
深市:
http://www.szse.cn/disclosure/listed/fixed/index.html
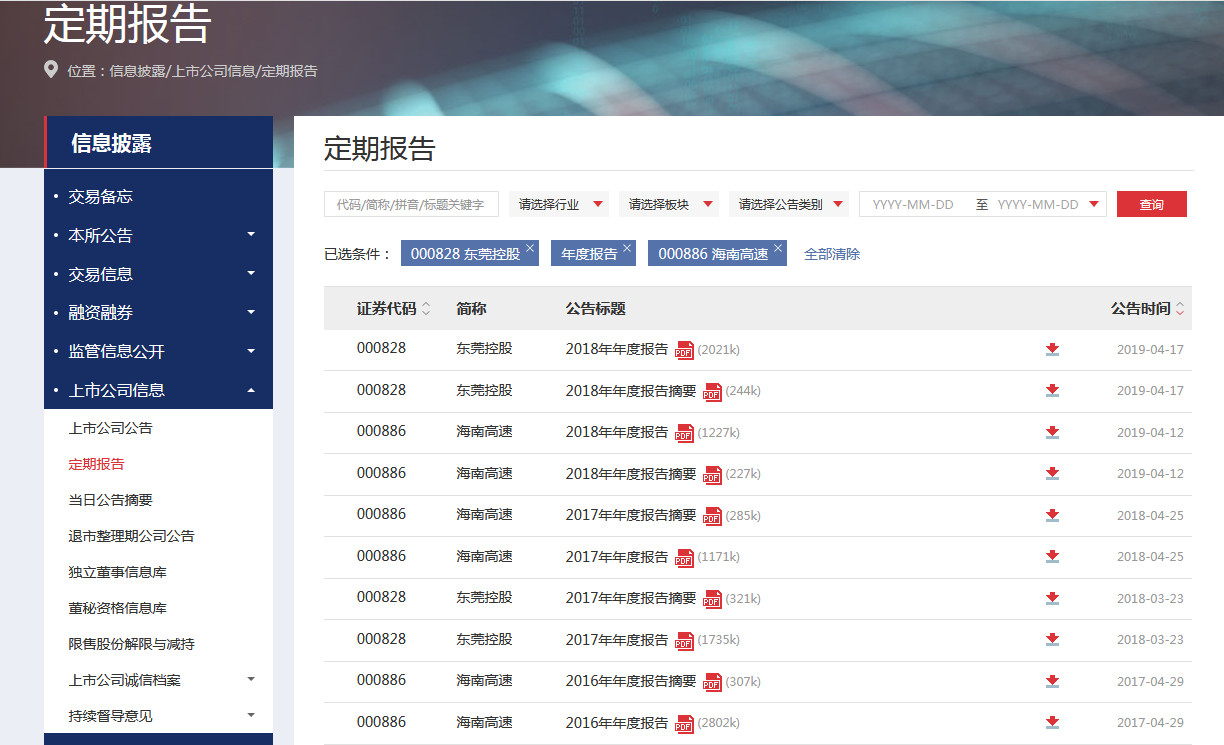
三、源码下载
#coding:utf-8
import re
import urllib.request
import random
import os
def html_f(code):
url = 'http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/%s/page_type/ndbg.phtml'%code
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
return html
def targrt_f(html):
target = r'&id=[0-9]{7}'
#target1 = r'&id=[0-9]{6}'
target_l = re.findall(target,html)# + re.findall(target1,html)
print(target_l)
return target_l
def title_f(html):
title = re.compile(r">(.*?)</a><br>")
item = re.findall(title,html)
print(item)
return item
def download(target,path,name):
url = 'http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=000048%s'%target
url_html = urllib.request.urlopen(url).read().decode('gbk')
target_pdf = re.findall("http://file.finance.sina.com.cn/211.154.219.97:9494/MRGG/CNSESZ_STOCK/.*?.PDF",url_html)
try:
print(target_pdf[0])
# local =r'%s.pdf'%name.encode('gbk')
# x = random.randint(0,999999)
urllib.request.urlretrieve(target_pdf[0],path+'\\%s.pdf' % name)
except: print("pass")
codes=['000885','600035','600012','600033','000900','600003','200429','000916','601188','000548','600350']
code2 = ['601518','000755','600106','601107','000828','001965','600269','000429','600368','600548','600020','600377]']
for code in codes:
mkpath="C:\\Users\\Administrator\\Desktop\\e\\{}".format(code)
path = os.makedirs(mkpath)
html = html_f(code)
target_list = targrt_f(html)
name = title_f(html)
if len(target_list) < len(name):
name[len(target_list)] = name[0:len(target_list)]
for each,title in zip(target_list,name):
print(each,title)
download(each,mkpath,title)
四、生成股票列表
import sys
result=[]
with open('stock.txt','r') as f:
for line in f:
result.append(line.strip('\n').split(',')[0])
print(result)